4.2 مليون requests في 24 ساعة. متوسط الـ response هو 774 ms. معدل النجاح: 99.91%. بلغ متوسط الـ workload نفسه 2.5 ثانية طوال الأيام السبعة التي سبقت إعادة البناء. يمثل هذا انخفاضاً بنسبة 70% في متوسط الـ response time، على نفس الـ hardware، وضد نفس المواقع المستهدفة، ومع نفس الـ proxy pool. لقد أعدنا بناء أجزاء الـ request path التي كانت تكلف العملاء أمسياتهم بهدوء.
هذا تقرير عما تغير، وكيف تبدو الأرقام فعلياً، وأين يختلف Single و Proxy Finder لسبب وجيه.
ملاحظة بشأن البيانات أولاً. الأرقام الواردة في هذا المنشور مأخوذة من الـ production traffic، مع استبعاد target host واحد محدد. كان هذا الـ host يطبق الـ rate-limiting بفاعلية ويتحدى الـ requests طوال الأسبوع، مما يؤدي إلى تشويه كل مقياس تنظر إليه. إذا قمنا بتضمينه، سينخفض معدل النجاح إلى حوالي 95%. لكن هذه الفجوة البالغة 5% ليست فشلاً في الـ infrastructure لدينا. بل هي موقع واحد يرفض الـ requests، بغض النظر عن مدى جودة الـ picker لدينا. لقد استبعدناه لتتمكن من رؤية ما يفعله النظام فعلياً مع الأهداف المتعاونة.
ما تظهره البيانات
إليك المتوسط اليومي عبر الـ production traffic لدينا للأسبوع الماضي:
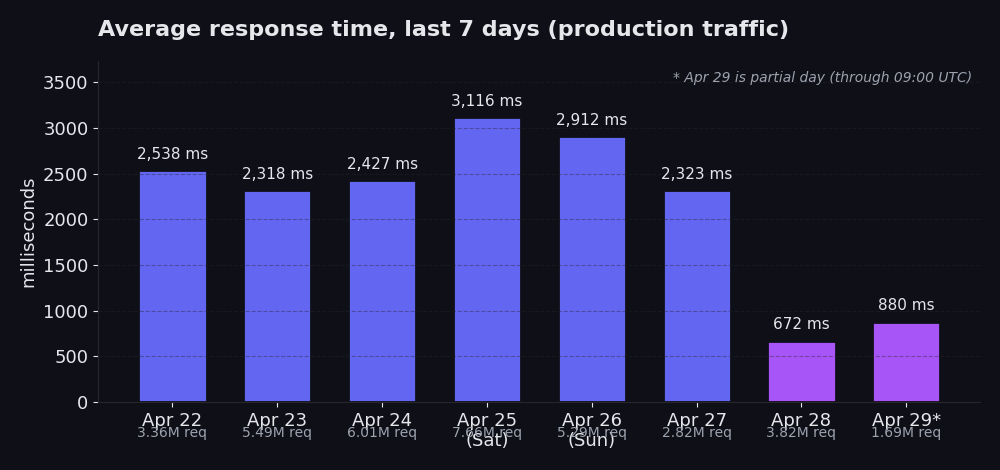
من 22 أبريل إلى 27 أبريل: تراوحت المتوسطات بين 2,318 ms و 3,116 ms، وتراوح الـ traffic بين 2.8M و 7.7M requests يومياً. تميز يوم 25 أبريل بـ 3,116 ms عبر 7.7M requests، وهو ذروة يوم السبت (حيث يرتفع حجم الـ traffic في عطلة نهاية الأسبوع بشكل ملحوظ ويدفع المتوسط للأعلى). 28 أبريل: 672 ms عبر 3.8M requests. 29 أبريل (جزء من اليوم، حتى الساعة 09:00 UTC): 880 ms عبر 1.7M requests حتى الآن.
نفس الـ architecture. نفس الـ proxies. نفس المواقع المستهدفة. الـ request path مختلف.
صورة الـ percentiles أكثر وضوحاً من المتوسط. يمكن للمتوسطات أن تخفي الـ bad tails. أما الـ percentiles فلا يمكنها ذلك.
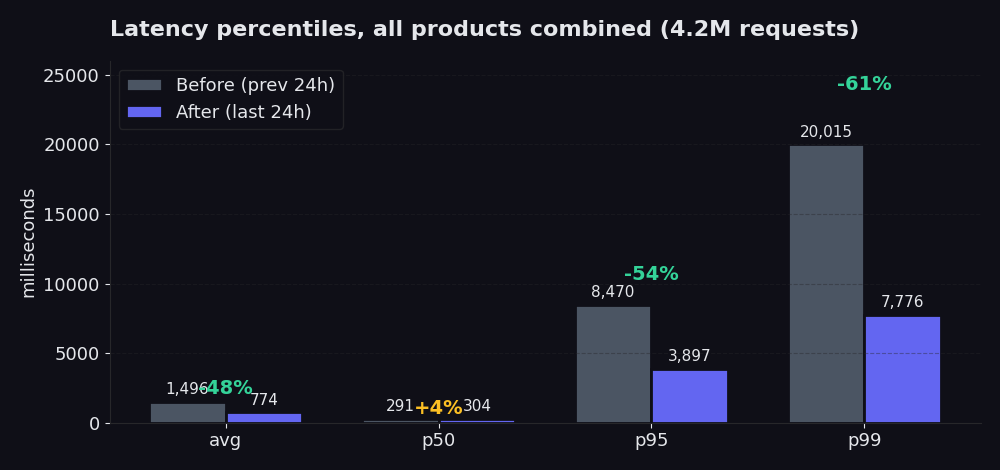
يقارن المخطط الـ 24 ساعة التي تلت إعادة البناء بالـ 24 ساعة التي سبقتها. لم يتحرك p50 تقريباً (وارتفع بنسبة 4%، وهي بيانات صادقة؛ حيث كان الـ fast path جيداً بالفعل ويبذل الـ picker الجديد جهداً أكبر قليلاً في البداية لتوفير الكثير في الـ tail). انخفض المتوسط بنسبة 48% في تلك النافذة الزمنية. وانتقل p95 من 8.5 ثانية إلى 3.9 ثانية، وهو تقليص بنسبة 54%. وانتقل p99 من 20 ثانية إلى 7.8 ثانية، وهو تقليص بنسبة 61%. هذا هو مكمن الألم، وهذا ما تشعر به فعلياً عندما ينتظر الـ scraper الخاص بك عودة أبطأ 5% من الـ requests. وبالمقارنة مع الأيام السبعة التي سبقت إعادة البناء (حيث استقر المتوسط عند حوالي 2.5 ثانية)، فإن متوسط اليوم البالغ 774 ms يمثل انخفاضاً بنسبة 70%.
ارتفع معدل النجاح أيضاً: من 98.85% إلى 99.91% خلال نفس النافذة الزمنية. في Proxy Finder تحديداً، وصل المعدل إلى 99.89%. وفي Single، وصل إلى 99.96%. هذا هو الرقم الذي نفخر به للغاية، لأنه يوضح لك عدد المرات التي نعيد فيها بيانات مفيدة في المحاولة الأولى دون الحاجة إلى الـ retry.
منتجان، وملفان مختلفان لـ latency
نحن لا نقارن بين Single و Proxy Finder. فهما يحلان مشكلتين مختلفتين ولديهما latency budgets مختلفة. إذا كنت تستخدم أحدهما وتنظر إلى أرقام الآخر، فأنت تقرأ لوحة النتائج الخاطئة.
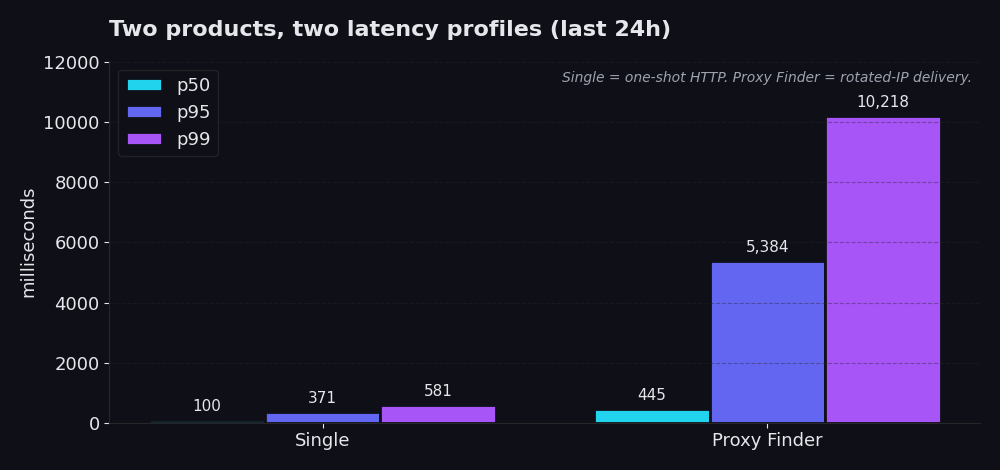
Single هو عبارة عن request HTTP لمرة واحدة عبر الـ infrastructure لدينا. أنت تمنحنا URL، وفي حوالي 99% من استدعاءات الـ production الفعلية، تمنحنا proxy id تعرف مسبقاً أنه يعمل. نقوم بجلب الـ URL عبر هذا الـ proxy، وتحصل أنت على الـ response. لا يوجد rotation logic، ولا توجد retry cascade، ولا يوجد proxy churn. آخر 24 ساعة: p50 يبلغ 100 ms، و p95 يبلغ 371 ms، و p99 يبلغ 581 ms. تنتهي معظم الاستدعاءات في أقل من خمس ثانية. وحتى أسوأ 1% يعود في أقل من 600 ms.
Proxy Finder هو الـ discovery layer. يقوم بتدوير الـ request الخاص بك عبر pool من الـ proxies العامة، ويتحقق من صحة كل مرشح، ويعيد المحاولة عند الفشل، ويعيد أول response نجح بالفعل، بالإضافة إلى الـ proxy id الذي قام بذلك. p50 يبلغ 445 ms، و p95 يبلغ 5.4 ثانية، و p99 يبلغ 10.2 ثانية. إنه أبطأ لأن عليه أن يكون كذلك. الفكرة بأكملها هي أن الـ IP الذي يستخدمه الـ scraper الخاص بك للوصول إلى الموقع المستهدف هو عنوان مدور، ومؤقت، وقابل للتخلص منه. أنت تستبدل بضع ثوانٍ من الـ overhead بالمرونة ضد الـ block lists والـ rate limits.
السبب في سرعة Single ليس سحراً. بل لأن Single يثق في شيء كان على Proxy Finder اكتشافه. عندما تستدعي Proxy Finder مرة واحدة ويعيد "this proxy worked, here's its id"، فإن عمليات الجلب اللاحقة لنفس الهدف عبر Single تتخطى خطوة الاكتشاف بأكملها. تذهب مباشرة إلى الـ proxy الذي اجتاز التحقق بالفعل.
كيف تستخدمهما الفرق معاً
تتبع معظم الفرق التي تستهدف موقعاً بشكل متكرر نمطاً يتكون من خطوتين. الاستدعاء الأول يكون استكشافياً، وباقي الاستدعاءات تكون ملتزمة بالمسار المحدد.
الاستدعاء الأول يذهب إلى Proxy Finder. حيث يقوم بالتدوير عبر الـ pool، والتحقق من صحة كل مرشح مقابل الـ accept rules الخاصة بك، ويعيد الـ response مع الـ proxy id الذي نجح. هذا المعرف هو الـ handle الخاص بك لأي استدعاء مستقبلي يريد الوصول إلى نفس الهدف.
كل استدعاء بعد ذلك يذهب إلى Single، مع إرفاق الـ proxy id. لا اكتشاف، ولا تحقق، ولا retry cascade. نقوم بتوجيه الـ request الخاص بك عبر الـ proxy الذي حددته ونقوم ببث الـ response إليك. هذا هو المسار الذي يصل إلى 100 ms عند p50.
عندما يتم حظر الـ proxy الذي كان يعمل بالأمس اليوم، فإنك تتراجع إلى Proxy Finder لاستدعاء واحد لإعادة الاكتشاف، ثم تستأنف عمليات جلب Single باستخدام المعرف الجديد. نحن لا نغطي على الـ staleness. إذا كان الـ proxy id الذي سلمته لنا معطلاً، فسنخبرك بذلك بسرعة لتتمكن من التدوير.
تقسيم 99/1 (حيث يهيمن Single في الحجم، ويهيمن Proxy Finder في الاكتشاف) هو السبب في أن أرقام Single لدينا تبدو على هذا النحو. لا يعني ذلك أن Single منتج أسرع بطبيعته. بل لأن Single يمثل الـ steady state بينما Proxy Finder هو الـ calibration step. معظم الـ workloads تكون في الغالب في الـ steady state.
إذا كانت مهمتك هي "جلب هذا الـ JSON من API عام ونظيف لا يهتم بمن يستدعيه"، فتخط الـ proxy تماماً واستخدم Single بمفرده. وإذا كانت مهمتك هي "الوصول إلى هذه الصفحة المحمية من pool من الـ IPs القابلة للتخلص منها دون أن يتم كشفك"، فقم بدمجهما معاً. فهما ليسا بديلين، بل هما مرحلتان من نفس الـ workflow.
ما قمنا بتغييره
جاء معظم الفوز من إعادة بناء ثلاثة أشياء في مسار تدوير الـ proxy. لم تكن أي منها أفكاراً جديدة، بل كانت مجرد أمور قمنا بتأجيلها.
توقف الـ pool عن الثقة بالبيانات السيئة. قبل إعادة البناء، كان دليل الـ proxy يحتفظ بالمدخلات لفترة أطول مما ينبغي. ولم يعد من الممكن الوصول إلى بعض تلك المدخلات. وكان اختيار أحدها يعني قضاء 15 إلى 30 ثانية لاكتشاف ذلك بالطريقة الصعبة. لقد انتقلنا إلى نموذج يعكس فيه الـ pool ما هو نشط بالفعل في الوقت الفعلي تقريباً، ويفضل الـ picker عناوين الـ IPs التي رأينا نجاحها مؤخراً.
درجات جودة لكل proxy، وليس مجرد حالة عمل أو توقف. في السابق، كان الـ proxy الذي يستغرق 5 ثوانٍ للـ response يبدو مثل الـ proxy الذي يستغرق 300 ms، طالما أن كلاهما ينجح في النهاية. الآن يتبع الـ picker الـ latency أيضاً. يتم دفع الـ proxies البطيئة ولكن العاملة إلى أسفل الـ queue. ويتم إعادة استخدام الـ proxies السريعة وهي لا تزال hot. هذا الأمر أكثر أهمية مما يبدو، لأن الـ long tail لتوزيع الـ latency هو في الغالب proxies بطيئة ولكنها تعمل، والتي استمر الـ picker القديم في اختيارها.
درجات جودة لكل target. قد يكون الـ proxy الموثوق به على domain معين غير مستقر على domain آخر. وعناوين الـ IPs التي تعمل بنظافة ضد موقع ما قد يتم حظرها أو تطبيق الـ rate-limiting عليها في موقع آخر. يتبع الـ picker لدينا الآن النجاح والـ latency لكل target host، وليس فقط على المستوى العالمي. عندما تطلب جلب بيانات ضد domain معين، فإننا نختار من الـ proxies التي كان أداؤها جيداً بالفعل على ذلك الـ domain مؤخراً. تظل الـ proxies الجيدة عالمياً في المنافسة، ولكن الـ proxy الذي يتمتع بسجل حافل قوي على الـ target المحدد يتفوق على الـ proxy الذي يتمتع بسجل حافل قوي بشكل عام.
تصعيد أكثر ذكاءً للـ retry. عندما يفشل الـ request، كنا نقوم بنشر محاولات متوازية على الفور. كان ذلك هدراً، والأسوأ من ذلك، أن proxy سيئاً واحداً كان يمكن أن يتسبب في سلسلة من المتابعات التي تفشل بدورها. الآن تتصاعد الـ retries بالتتابع مع backoffs قصيرة بين المحاولات، بحيث يكون الفشل فشلاً والـ retry هو retry، وليس مضاعِفاً للأخطاء.
هناك فئة ثانية من التغييرات التي تستحق الذكر، على الرغم من أنها أقل وضوحاً بالنسبة لك.
المرونة عند إعادة التشغيل (Restart resilience). في السابق، كانت إعادة نشر (redeploying) أي جزء من الـ request infrastructure لدينا تعني نافذة زمنية تتراوح بين 5 إلى 15 دقيقة حيث يتعين على خريطة درجات جودة الـ proxy إعادة بناء نفسها من الصفر. خلال تلك النافذة، كان الـ picker يخمن بشكل أساسي. وكان العملاء يرون ذلك على أنه latency spike مباشرة بعد كل deploy. نحن الآن نحفظ خريطة الجودة تلك عبر الـ restarts. يبدأ النظام وهو warm. بدءاً من اليوم، يمكننا deploy تغييرات الـ infrastructure في منتصف اليوم دون التسبب في latency spike. أظهر اختبار الـ restart الذي أجريناه هذا الصباح خللاً مؤقتاً في الاتصال لمدة 15 ثانية ووقت استرداد صفري بعد ذلك. هذا تغيير هادئ ولكنه مهم في الـ deploy cadence لدينا: لم نعد مضطرين لجدولة عمليات إعادة النشر بناءً على الـ traffic الخاص بك.
إشارات فشل أكثر وضوحاً. عندما يحدث خطأ ما داخل الـ infrastructure لدينا، يحصل الـ retry logic الخاص بك الآن على الـ HTTP status code الصحيح للتصرف بناءً عليه. يعيد الـ backend غير المتاح مؤقتاً الرمز 503. ويعيد الـ backend الذي أرجع JSON مشوهاً (malformed) الرمز 502. ويعيد الخطأ الداخلي الحقيقي الرمز 500. في السابق، كانت الحالات الثلاث تبدو كرموز 500، مما يعني أن الـ retry logic الخاص بك لم يكن بإمكانه التمييز بين "wait and try again" وبين "this is broken, escalate". الآن يمكنه ذلك.
كيف يبدو هذا بالنسبة لك
إذا كنت تقوم بتشغيل scrapers ضد proxies مدورة، فإن التغيير العملي هو أن كلاً من p95 و p99 لديك قد تم تقليصهما إلى النصف تقريباً مقارنة بالأسبوع الماضي. ينخفض متوسط وقت الـ request. وتنخفض الـ retries الناتجة عن الـ proxies البطيئة ولكنها تعمل في النهاية. وينخفض معها الـ tail latency، وهو ما يجعل مهمة مكونة من 1,000 requests تستغرق ساعة بدلاً من 20 دقيقة.
إذا كنت تقوم بتشغيل Single، فسترى ثمار عمل الـ picker تظهر في الغالب عند الـ tail. حيث انخفض p99 إلى أقل من 600 ms، مما يعني أنه حتى الـ 1% غير المحظوظة من الـ requests لديك تعود الآن بسرعة. كان Single سريعاً بالفعل، ولكنه أصبح الآن متسقاً.
قيود بكل صراحة
لم نقم بإصلاح كل شيء. لا تزال هناك بعض التفاصيل المحددة التي تنطبق:
لا يزال p99 لـ Proxy Finder حوالي 10 ثوانٍ. لقد قلصناه إلى النصف، لكن الـ long tail حقيقي. جزء من ذلك يقع على عاتقنا (عمق الـ pool، وتشويش الـ picker على الأهداف النادرة). والكثير منه ليس كذلك: يمكن للمواقع المستهدفة أن تكون بطيئة بمفردها، أو يمكنها تطبيق الـ rate-limit على مسارات معينة، أو يمكنها تقديم صفحات تحدي (challenge pages) تستغرق وقتاً لفحصها، أو يمكنها ببساطة أن يحدث لها timeout. يمكن للـ infrastructure لدينا اختيار أفضل IP متاح، لكنها لا تستطيع تسريع خادم مستهدف يقرر ما إذا كان سيجيب أم لا. إذا كان عملك يعتمد على عودة كل request في أقل من 5 ثوانٍ، فقم بتعيين per-request timeout تتوافق مع مدى تحملك وثق في الـ retry layer.
بعض الأهداف معادية، ويظهر ذلك في أرقامك. كما ذكرنا في البداية، فإن معدل النجاح البالغ 99.91% يستبعد host واحداً يتحدانا بفاعلية هذا الأسبوع. وتضمينه يخفض المعدل إلى حوالي 95%. هذا الـ host ليس فريداً من نوعه. أي aggregator يعمل مع بيانات الويب العامة يرى هذا. يتغير الـ target من أسبوع لآخر. تمنح إعادة بناء الـ picker النظام فرصة أفضل بكثير للتوجيه حول الأهداف المعادية، لكنها لا تستطيع تجاوز موقع قرر رفض الـ traffic تماماً. مهمتنا هي تزويدك بأنظف بيانات ممكنة في الحالات المتعاونة، والـ fail fast في الحالات المعادية.
مقارنة نفس اليوم تحتوي على noise. النافذة الزمنية البالغة 24 ساعة التي نعرضها في مخطط الـ percentiles تقارن يوم أمس باليوم الذي قبله. تتغير تأثيرات أيام الأسبوع، واختلاف المواقع المستهدفة، وتكوين الـ pool بين أي نافذتين زمنيتين. نحن واثقون من الاتجاه (يظهر مخطط الـ 7 أيام inflection point واضحة في 28 أبريل)، ولكن إذا كنت تقارننا بـ workload الخاص بك، فقم بإجراء المقارنة على مدار أسبوع على الأقل.
ما الخطوة التالية
إعادة كتابة الـ picker هي الأساس. وهناك بعض الأشياء التي وضعناها في قائمة الانتظار بعدها:
خريطة درجات جودة مشتركة عبر الـ instances، بحيث تتعلم من بعضها البعض بدلاً من بناء خرائط مستقلة. في الوقت الحالي، تحمل كل منها صورتها الخاصة عن الـ proxies الجيدة. هذا يعمل، لكنه هدر: تدفع كل instance نفس تكلفة التعلم بالتوازي.
الاختيار القائم على الثقة (Confidence-based picking)، حيث نفضل الـ proxies التي اختبرناها بالفعل في الدقائق القليلة الماضية على تلك التي نخمن بشأنها. هذا مفيد للعملاء ذوي حجم الـ traffic المنخفض الذين لا يحافظ الـ traffic الخاص بهم على نشاط الـ picker (warm) بمفرده.
وعلى المدى الأطول: دفع المزيد من القرارات إلى الـ picker بحيث تصبح الـ per-target quality score إشارة واحدة من بين إشارات عديدة (مثل ملف الـ latency للـ target، وأنماط الوقت من اليوم، وصحة شريحة الـ pool). الـ infrastructure موجودة الآن للقيام بذلك دون إبطاء الـ hot path.
الـ request الأقل تكلفة هو الـ request الذي لم نضطر إلى إعادة محاولته. إعادة بناء الـ picker هي الرهان على أن البيانات الأفضل في لحظة الاختيار تتفوق على المزيد من المحاولات بعد فوات الأوان. وتشير أدلة أول 24 ساعة إلى أنه الرهان الصحيح.