4,2 Millionen Requests in 24 Stunden. Durchschnittliche Antwortzeit: 774 ms. Erfolgsquote: 99,91 %. Derselbe Workload lag in den sieben Tagen vor unserem Rebuild im Schnitt bei 2,5 Sekunden. Das ist ein Rückgang der durchschnittlichen Antwortzeit um 70 % auf derselben Hardware, gegen dieselben Zielseiten und mit demselben Proxy-Pool. Wir haben die Teile des Request-Pfads neu gebaut, die Kunden stillschweigend ihren Feierabend gekostet haben.
Dies ist ein Bericht darüber, was sich geändert hat, wie die Zahlen tatsächlich aussehen und warum sich Single und Proxy Finder aus gutem Grund unterscheiden.
Zuerst ein Hinweis zu den Daten. Die Zahlen in diesem Beitrag stammen aus dem Produktiv-Traffic, wobei ein bestimmter Ziel-Host ausgeschlossen wurde. Dieser Host hat die ganze Woche über aktiv Rate-Limits angewendet und Requests mit Challenges blockiert, was jede Metrik verzerrt. Wenn man ihn einbezieht, sinkt die Erfolgsquote auf etwa 95 %. Aber diese 5 % Differenz sind kein Ausfall unserer Infrastruktur. Es ist eine einzelne Seite, die Requests ablehnt, egal wie gut unser Picker ist. Wir haben sie herausgerechnet, damit du siehst, was das System auf kooperativen Zielseiten tatsächlich leistet.
Was die Daten zeigen
Hier ist der tägliche Durchschnitt unseres Produktiv-Traffics der letzten Woche:
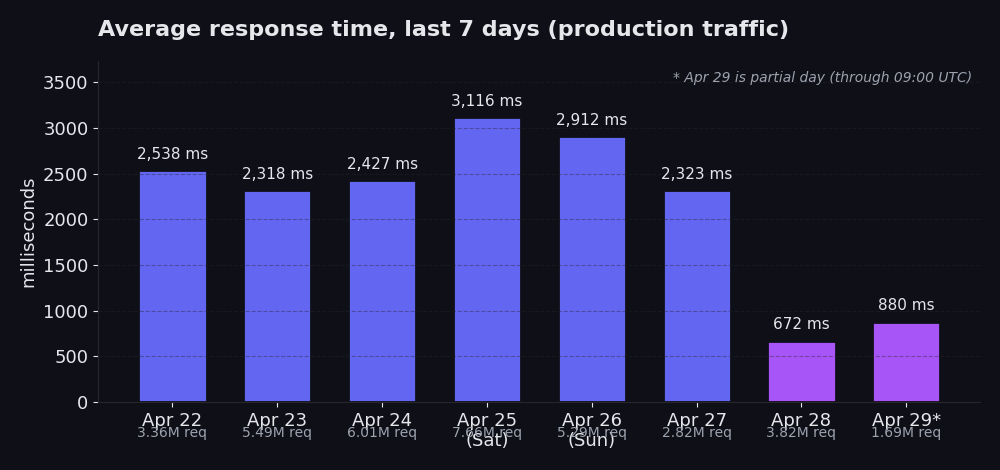
- bis 27. April: Durchschnitte zwischen 2.318 ms und 3.116 ms, Traffic zwischen 2,8 Mio. und 7,7 Mio. Requests pro Tag. Der 25. April sticht mit 3.116 ms bei 7,7 Mio. Requests heraus, was dem Samstags-Peak entspricht (das Wochenendvolumen ist spürbar höher und treibt den Durchschnitt nach oben). 28. April: 672 ms bei 3,8 Mio. Requests. 29. April (unvollständiger Tag, bis 09:00 UTC): bisher 880 ms bei 1,7 Mio. Requests.
Dieselbe Architektur. Dieselben Proxys. Dieselben Zielseiten. Anderer Request-Pfad.
Das Bild der Perzentile ist deutlicher als der Durchschnitt. Durchschnitte können Ausreißer am Ende verbergen. Perzentile nicht.
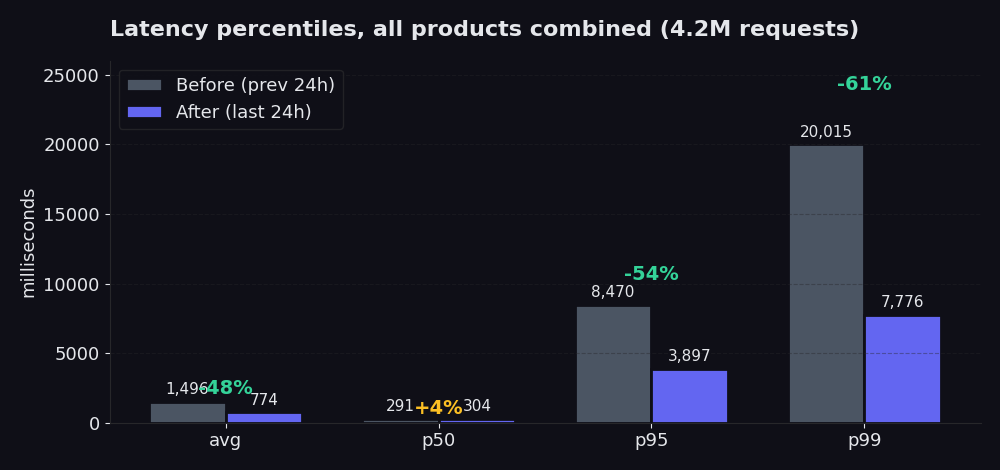
Das Diagramm vergleicht die 24 Stunden nach unserem Rebuild mit den 24 Stunden davor. Der p50-Wert hat sich kaum verändert (und stieg um 4 %, was ehrliche Daten sind; der schnelle Pfad war bereits in Ordnung, und der neue Picker investiert anfangs etwas mehr Aufwand, um am Ende viel einzusparen). Der Durchschnitt sank in diesem Fenster um 48 %. Der p95-Wert sank von 8,5 Sekunden auf 3,9 Sekunden, eine Reduzierung um 54 %. Der p99-Wert sank von 20 Sekunden auf 7,8 Sekunden, eine Reduzierung um 61 %. Genau dort liegt der Schmerz, und das ist es, was du tatsächlich spürst, wenn dein Scraper auf die langsamsten 5 % der Requests wartet. Verglichen mit den sieben Tagen vor dem Rebuild (in denen der Durchschnitt bei etwa 2,5 Sekunden lag), ist der heutige Durchschnitt von 774 ms ein Rückgang um 70 %.
Auch die Erfolgsquote stieg im selben Zeitraum von 98,85 % auf 99,91 %. Speziell bei Proxy Finder erreichte die Quote 99,89 %. Bei Single waren es 99,96 %. Das ist die Zahl, auf die wir am stolzesten sind, denn sie zeigt dir, wie oft wir beim ersten Versuch brauchbare Daten zurückgeben, ohne es erneut versuchen zu müssen.
Zwei Produkte, zwei Latenzprofile
Wir vergleichen Single und Proxy Finder nicht miteinander. Sie lösen unterschiedliche Probleme und haben unterschiedliche Latenzbudgets. Wenn du das eine nutzt und auf die Zahlen des anderen schaust, liest du die falsche Anzeigetafel.
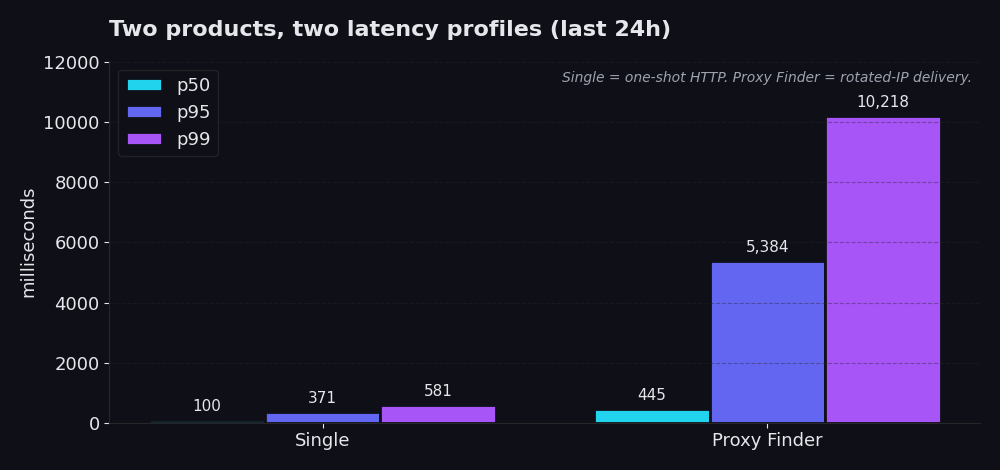
Single ist ein One-Shot-HTTP-Request durch unsere Infrastruktur. Du gibst uns eine URL und (in rund 99 % der echten Produktiv-Aufrufe) eine Proxy-ID, von der du bereits weißt, dass sie funktioniert. Wir rufen die URL über diesen Proxy ab, du erhältst die Response. Keine Rotationslogik, keine Retry-Kaskade, kein Proxy-Churn. Letzte 24 Stunden: p50 von 100 ms, p95 von 371 ms, p99 von 581 ms. Die meisten Aufrufe sind in weniger als einer Fünftelsekunde abgeschlossen. Selbst das schlechteste 1 % kommt in unter 600 ms zurück.
Proxy Finder ist der Discovery-Layer. Er rotiert deinen Request über einen Pool öffentlicher Proxys, validiert jeden Kandidaten, führt bei Fehlern Retries durch und gibt die erste tatsächlich funktionierende Response zurück, zusammen mit der ID des Proxys, der sie geliefert hat. p50 von 445 ms, p95 von 5,4 Sekunden, p99 von 10,2 Sekunden. Langsamer, weil es so sein muss. Der springende Punkt ist, dass die IP, mit der dein Scraper die Zielseite aufruft, rotiert, temporär und austauschbar ist. Du tauschst ein paar Sekunden Overhead gegen Resistenz gegen Blocklisten und Rate-Limits.
Dass Single so schnell ist, ist keine Magie. Es liegt daran, dass Single auf etwas vertraut, das Proxy Finder erst entdecken musste. Wenn du Proxy Finder einmal aufrufst und es „dieser Proxy hat funktioniert, hier ist seine ID“ zurückgibt, überspringen nachfolgende Abrufe desselben Ziels über Single den gesamten Discovery-Schritt. Du gehst direkt zu dem Proxy, der die Validierung bereits bestanden hat.
Wie Teams sie zusammen nutzen
Die meisten Teams, die ein Ziel häufig anfragen, folgen einem zweistufigen Muster. Der erste Aufruf ist explorativ, die restlichen sind gesetzt.
Der erste Aufruf geht an Proxy Finder. Er rotiert durch den Pool, validiert jeden Kandidaten anhand deiner Accept-Rules und gibt die Response zusammen mit der ID des funktionierenden Proxys zurück. Diese ID ist dein Handle für jeden zukünftigen Aufruf desselben Ziels.
Jeder weitere Aufruf geht an Single, mit angehängter Proxy-ID. Kein Discovery, keine Validierung, keine Retry-Kaskade. Wir leiten deinen Request durch den von dir angegebenen Proxy und streamen die Response zurück. Das ist der Pfad, der beim p50-Wert 100 ms erreicht.
Wenn der Proxy, der gestern noch funktionierte, heute blockiert wird, weichst du für einen Aufruf auf Proxy Finder aus, um ihn neu zu entdecken, und setzt dann die Single-Abrufe mit der neuen ID fort. Wir vertuschen veraltete Daten nicht. Wenn eine Proxy-ID, die du uns übergeben hast, tot ist, teilen wir dir das schnell mit, damit du rotieren kannst.
Der 99/1-Split (Single dominiert beim Volumen, Proxy Finder bei der Discovery) ist der Grund, warum unsere Single-Zahlen so aussehen. Es ist nicht so, dass Single an sich ein schnelleres Produkt ist. Vielmehr ist Single der Normalbetrieb und Proxy Finder der Kalibrierungsschritt. Die meisten Workloads befinden sich meistens im Normalbetrieb.
Wenn deine Aufgabe lautet „rufe dieses JSON von einer sauberen, öffentlichen API ab, der es egal ist, wer anfragt“, überspringe den Proxy komplett und nutze Single allein. Wenn deine Aufgabe lautet „rufe diese geschützte Seite aus einem Pool von Einweg-IPs ab, ohne blockiert zu werden“, kombiniere beide. Sie sind keine Alternativen. Sie sind Phasen desselben Workflows.
Was wir geändert haben
Der Großteil des Gewinns resultierte aus dem Rebuild von drei Dingen im Proxy-Rotationspfad. Nichts davon waren neue Ideen. Es waren einfach Dinge, die wir vor uns hergeschoben hatten.
Der Pool vertraut schlechten Daten nicht mehr. Vor dem Rebuild behielt das Proxy-Verzeichnis Einträge länger als nötig. Einige dieser Einträge waren gar nicht mehr erreichbar. Einen davon auszuwählen bedeutete, dass man 15 bis 30 Sekunden lang auf die harte Tour lernen musste. Wir sind zu einem Modell gewechselt, bei dem der Pool nahezu in Echtzeit widerspiegelt, was tatsächlich aktiv ist, und der Picker IPs bevorzugt, die wir kürzlich erfolgreich gesehen haben.
Quality-Scores pro Proxy, nicht nur Up-or-Down. Vorher sah ein Proxy, der 5 Sekunden für eine Antwort brauchte, genauso aus wie einer, der 300 ms brauchte, solange beide letztendlich erfolgreich waren. Jetzt erfasst der Picker auch die Latenz. Langsame, aber funktionierende Proxys werden in der Queue nach hinten geschoben. Schnelle werden wiederverwendet, solange sie warm sind. Das ist wichtiger als es klingt, denn das lange Ende der Latenzverteilung besteht hauptsächlich aus langsamen, aber funktionierenden Proxys, die der alte Picker immer wieder ausgewählt hat.
Zielspezifische Quality-Scores. Ein Proxy, der auf einer Domain zuverlässig ist, kann auf einer anderen unzuverlässig sein. Die IPs, die auf einer Seite sauber funktionieren, werden auf einer anderen blockiert oder mit Rate-Limits belegt. Unser Picker erfasst Erfolg und Latenz jetzt pro Ziel-Host, nicht nur global. Wenn du einen Abruf für eine bestimmte Domain anforderst, wählen wir aus den Proxys, die auf dieser Domain kürzlich gut abgeschnitten haben. Global gute Proxys bleiben im Rennen, aber ein Proxy mit einer starken Erfolgsbilanz auf dem exakten Ziel sticht einen mit einer insgesamt guten Bilanz aus.
Intelligentere Retry-Eskalation. Wenn ein Request fehlschlug, haben wir früher sofort parallele Versuche gestartet. Das war verschwenderisch, und schlimmer noch: Ein einzelner schlechter Proxy konnte eine Kaskade von Folgeversuchen auslösen, die alle nacheinander fehlschlugen. Jetzt eskalieren Retries sequenziell mit kurzen Backoffs zwischen den Versuchen. So bleibt ein Fehler ein Fehler und ein Retry ein Retry, statt als Multiplikator zu wirken.
Es gibt eine zweite Kategorie von Änderungen, die erwähnenswert sind, auch wenn sie für dich weniger sichtbar sind.
Neustart-Resistenz. Zuvor bedeutete das Redeployment unserer Request-Infrastruktur ein Zeitfenster von 5 bis 15 Minuten, in dem sich die Proxy-Quality-Score-Map von Grund auf neu aufbauen musste. In diesem Fenster rät der Picker im Grunde nur. Kunden sahen das als Latenz-Spike direkt nach jedem Deploy. Wir persistieren diese Quality-Map jetzt über Neustarts hinweg. Das System startet warm. Ab heute können wir Infrastrukturänderungen mitten am Tag deployen, ohne dass es bei dir zu einem Latenz-Spike kommt. Der Neustart-Test, den wir heute Morgen durchgeführt haben, zeigte einen 15-sekündigen Verbindungs-Blip und danach keinerlei Erholungszeit. Das ist eine unauffällige, aber bedeutende Änderung unserer Deploy-Kadenz: Wir müssen Redeployments nicht mehr um deinen Traffic herum planen.
Sauberere Fehlersignale. Wenn in unserer Infrastruktur etwas schiefgeht, erhält deine Retry-Logik jetzt den richtigen HTTP-Statuscode, um darauf zu reagieren. Ein Backend, das kurzzeitig nicht verfügbar ist, gibt einen 503 zurück. Ein Backend, das fehlerhaftes JSON zurückgegeben hat, gibt einen 502 zurück. Ein echter interner Fehler gibt einen 500 zurück. Zuvor sahen alle drei wie 500er aus, was bedeutete, dass deine Retry-Logik „warten und erneut versuchen“ nicht von „das ist kaputt, eskalieren“ unterscheiden konnte. Jetzt kann sie es.
Was das für dich bedeutet
Wenn du Scraper mit rotierten Proxys betreibst, besteht die praktische Änderung darin, dass sich deine p95- und p99-Werte im Vergleich zur Vorwoche in etwa halbiert haben. Die durchschnittliche Request-Zeit sinkt. Retries aufgrund von langsamen, aber letztendlich funktionierenden Proxys nehmen ab. Die Tail-Latenz, die dafür sorgt, dass ein Job mit 1.000 Requests eine Stunde statt 20 Minuten dauert, sinkt ebenfalls.
Wenn du Single nutzt, wirst du sehen, dass sich die Arbeit am Picker vor allem am Ende auszahlt. Der p99-Wert sank auf unter 600 ms, was bedeutet, dass selbst dein unglückliches 1 % der Requests jetzt schnell zurückkommt. Single was already quick. It's now consistent.
Ehrliche Grenzen
Wir haben nicht alles behoben. Ein paar Besonderheiten, die weiterhin gelten:
Der p99-Wert von Proxy Finder liegt immer noch bei etwa 10 Sekunden. Wir haben ihn halbiert, aber das lange Ende ist real. Einiges davon liegt an uns (Pool-Tiefe, Picker-Rauschen bei seltenen Zielen). Vieles davon nicht: Zielseiten können von sich aus langsam sein, bestimmte Routen mit Rate-Limits belegen, Challenge-Seiten ausliefern, deren Überprüfung Zeit kostet, oder einfach in einen Timeout laufen. Unsere Infrastruktur kann die beste verfügbare IP auswählen, aber sie kann einen Zielserver nicht beschleunigen, der gerade entscheidet, ob er antwortet. Wenn dein Job darauf angewiesen ist, dass jeder Request in unter 5 Sekunden zurückkommt, setze ein Timeout pro Request, das deiner Toleranz entspricht, und vertraue dem Retry-Layer.
Einige Ziele sind feindselig, und das zeigt sich in deinen Zahlen. Wie eingangs erwähnt, schließt die Erfolgsquote von 99,91 % einen Host aus, der uns diese Woche aktiv blockiert. Wenn man ihn einbezieht, sinkt die Quote auf etwa 95 %. Dieser Host ist kein Einzelfall. Jeder Aggregator, der mit Public-Web-Daten arbeitet, kennt das. Das Ziel verschiebt sich von Woche zu Woche. Der Picker-Rebuild gibt dem System eine viel bessere Chance, feindselige Ziele zu umgehen, aber er kann keine Seite überstimmen, die sich entschieden hat, Traffic komplett zu verweigern. Unsere Aufgabe ist es, dir bei kooperativen Fällen die saubersten Daten zu liefern und bei feindseligen schnell abzubrechen.
Der Vergleich am selben Tag ist verrauscht. Das 24-Stunden-Fenster, das wir im Perzentil-Diagramm zeigen, vergleicht gestern mit vorgestern. Wochentagseffekte, Abweichungen bei den Zielseiten und die Pool-Zusammensetzung verschieben sich zwischen zwei Fenstern. Wir sind zuversichtlich, was die Richtung angeht (das 7-Tage-Diagramm zeigt einen deutlichen Wendepunkt am 28. April), aber wenn du uns mit deinem eigenen Workload vergleichst, ziehe den Vergleich über mindestens eine Woche.
Was kommt als Nächstes
Der Picker-Rewrite ist das Fundament. Einige Dinge, die wir dahinter in der Warteschlange haben:
Eine gemeinsam genutzte Quality-Score-Map über Instanzen hinweg, damit sie voneinander lernen, anstatt unabhängige Maps aufzubauen. Derzeit hat jede Instanz ihr eigenes Bild davon, welche Proxys gut sind. Das funktioniert, ist aber verschwenderisch: Jede Instanz zahlt parallel dieselben Lernkosten.
Vertrauensbasiertes Picking, bei dem wir Proxys bevorzugen, die wir in den letzten Minuten tatsächlich getestet haben, gegenüber solchen, bei denen wir nur raten. Nützlich für Kunden mit geringem Volumen, deren Traffic den Picker nicht von allein warmhält.
Und langfristig: Mehr Entscheidungen in den Picker verlagern, sodass der zielspezifische Quality-Score zu einem Signal unter vielen wird (Latenzprofil des Ziels, tageszeitliche Muster, Zustand des Pool-Segments). Die Infrastruktur ist nun vorhanden, um dies zu tun, ohne den schnellen Pfad zu verlangsamen.
Der günstigste Request ist der, den wir nicht wiederholen mussten. Der Picker-Rebuild ist die Wette, dass bessere Daten im Moment der Auswahl mehr Versuche im Nachhinein schlagen. Die Belege der ersten 24 Stunden zeigen, dass es die richtige Wette ist.