4,2 milhões de requests em 24 horas. Média de response: 774 ms. Taxa de sucesso: 99,91%. A mesma carga de trabalho teve média de 2,5 segundos nos sete dias anteriores à nossa reconstrução. Isso representa uma queda de 70% no tempo de response médio, no mesmo hardware, contra os mesmos sites de destino, com o mesmo pool de proxies. Reconstruímos as partes do request path que estavam silenciosamente custando as noites dos clientes.
Este é um relato do que mudou, como os números realmente se parecem e onde o Single e o Proxy Finder diferem por um motivo.
Uma observação sobre os dados primeiro. Os números neste post são do tráfego de produção, com um host de destino específico excluído. Esse host esteve ativamente aplicando rate limit e desafiando requests a semana toda, e ele distorce todas as métricas que você analisa. Se o incluirmos, o sucesso cai para cerca de 95%. Mas essa diferença de 5% não é uma falha da nossa infraestrutura. É um site recusando requests, independentemente de quão bom seja o nosso picker. Nós o removemos para que você possa ver o que o sistema realmente faz em alvos cooperativos.
O que os dados mostram
Aqui está a média diária do nosso tráfego de produção na última semana:
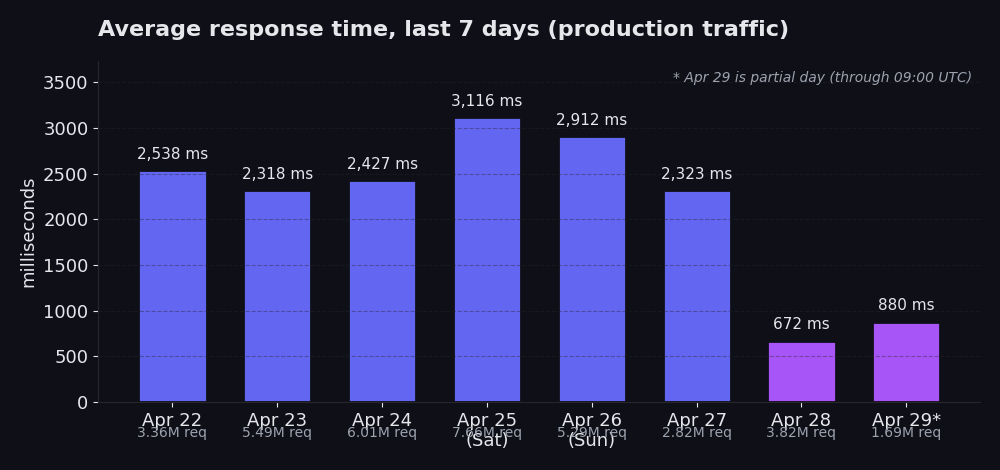
De 22 de abr a 27 de abr: médias entre 2.318 ms e 3.116 ms, tráfego entre 2,8M e 7,7M de requests por dia. O dia 25 de abr se destaca com 3.116 ms em 7,7M de requests, que é o pico de sábado (o volume de fim de semana é visivelmente maior e eleva a média). 28 de abr: 672 ms em 3,8M de requests. 29 de abr (dia parcial, até as 09:00 UTC): 880 ms em 1,7M de requests até o momento.
Mesma arquitetura. Mesmos proxies. Mesmos sites de destino. Diferente request path.
O cenário dos percentis é mais nítido do que a média. Médias podem esconder caudas ruins. Percentis não.
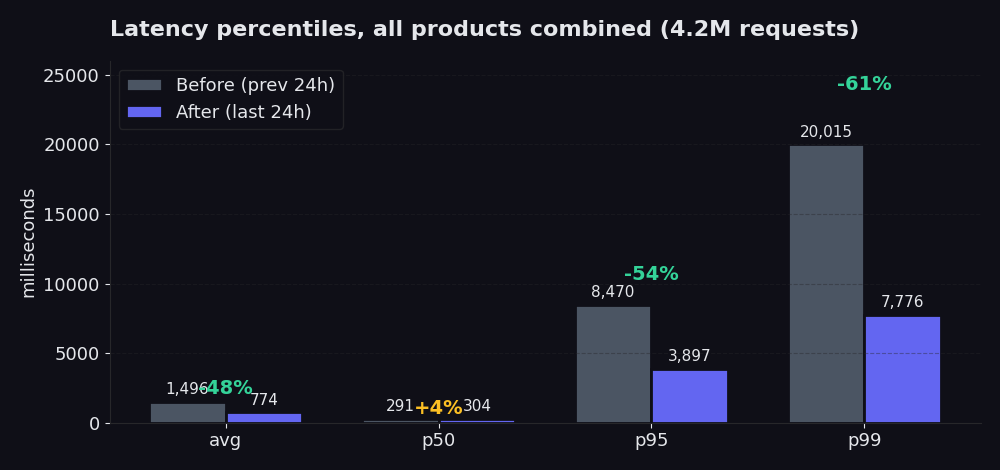
O gráfico compara as 24 horas após a nossa reconstrução com as 24 horas anteriores. O p50 quase não se moveu (e subiu 4%, o que são dados honestos; o caminho rápido já estava bom e o novo picker gasta um pouco mais de esforço no início para economizar muito na cauda). A média caiu 48% nessa janela. O p95 foi de 8,5 segundos para 3,9 segundos, uma redução de 54%. O p99 foi de 20 segundos para 7,8 segundos, uma redução de 61%. É aí que mora a dor, e é isso que você realmente sente quando seu scraper está esperando o retorno dos 5% mais lentos de requests. Comparado com os sete dias anteriores à reconstrução (onde a média se manteve em torno de 2,5 segundos), a média de hoje de 774 ms é uma queda de 70%.
A taxa de sucesso também subiu: de 98,85% para 99,91% na mesma janela. No Proxy Finder especificamente, a taxa atingiu 99,89%. No Single, 99,96%. Esse é o número do qual temos mais orgulho, porque ele mostra com que frequência entregamos de volta dados úteis na primeira tentativa, sem precisar de retry.
Dois produtos, dois perfis de latência
Nós não comparamos o Single e o Proxy Finder entre si. Eles resolvem problemas diferentes e têm orçamentos de latência diferentes. Se você está usando um e olhando para o número do outro, está lendo o placar errado.
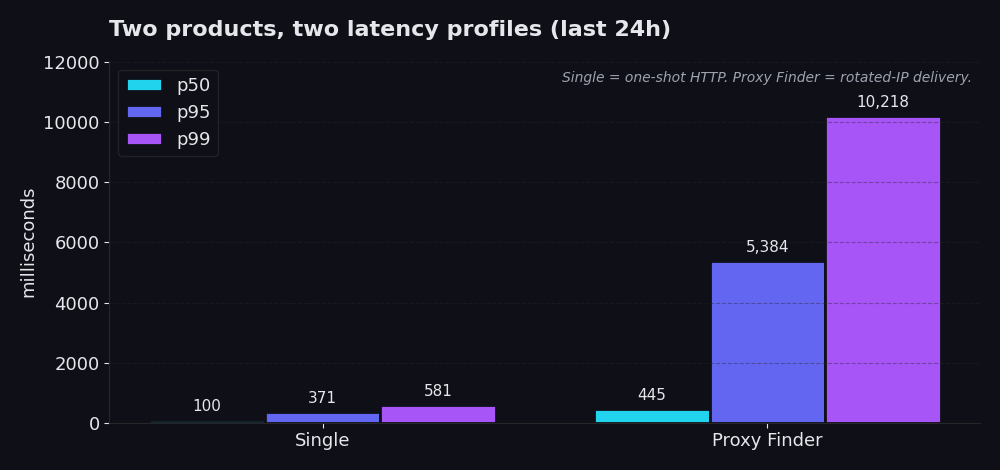
Single é um request HTTP direto pela nossa infraestrutura. Você nos fornece uma URL e, em cerca de 99% das chamadas reais de produção, um proxy id que você já sabe que funciona. Nós buscamos a URL através desse proxy, você recebe o response. Sem lógica de rotação, sem cascata de retry, sem churn de proxy. Últimas 24 horas: p50 de 100 ms, p95 de 371 ms, p99 de 581 ms. A maioria das chamadas termina em menos de um quinto de segundo. Mesmo o pior 1% retorna em menos de 600 ms.
Proxy Finder é a camada de descoberta. Ele rotaciona seu request por um pool de proxies públicos, valida cada candidato, faz retries em caso de falha e entrega de volta o primeiro response que realmente funcionou, além do id do proxy que fez isso. p50 de 445 ms, p95 de 5,4 segundos, p99 de 10,2 segundos. Mais lento porque precisa ser. O objetivo principal é que o IP com o qual seu scraper acessa o site de destino seja rotacionado, temporário e descartável. Você está trocando alguns segundos de overhead por resiliência contra block lists e rate limits.
A razão pela qual o Single é tão rápido não é mágica. É que o Single confia em algo que o Proxy Finder teve que descobrir. Quando você chama o Proxy Finder uma vez e ele retorna "este proxy funcionou, aqui está o id dele", as buscas subsequentes contra o mesmo alvo através do Single pulam toda a etapa de descoberta. Você vai direto para o proxy que já passou na validação.
Como as equipes os usam juntos
A maioria das equipes que acessam um alvo com frequência segue um padrão de duas etapas. A primeira chamada é exploratória; as demais são definitivas.
A primeira chamada vai para o Proxy Finder. Ele rotaciona pelo pool, valida cada candidato em relação às suas regras de aceitação e retorna o response junto com o id do proxy que funcionou. Esse id é o seu identificador para qualquer chamada futura que queira acessar o mesmo alvo.
Cada chamada depois disso vai para o Single, com o proxy id anexado. Sem descoberta, sem validação, sem cascata de retry. Nós roteamos seu request pelo proxy que você especificou e transmitimos o response de volta. Esse é o caminho que atinge 100 ms no p50.
Quando o proxy que funcionou ontem for bloqueado hoje, você recorre ao Proxy Finder para uma chamada de nova descoberta e, em seguida, retoma as buscas do Single com o novo id. Nós não mascaramos dados desatualizados. Se um proxy id que você nos passou estiver inativo, nós avisamos rapidamente para que você possa rotacionar.
A divisão 99/1 (Single dominante em volume, Proxy Finder dominante em descoberta) é a razão pela qual nossos números do Single parecem como parecem. Não é que o Single seja intrinsecamente um produto mais rápido. É que o Single é o estado estável e o Proxy Finder é a etapa de calibração. A maioria das cargas de trabalho está majoritariamente em estado estável.
Se a sua tarefa é "buscar este JSON de uma API pública limpa que não se importa com quem está chamando", pule o proxy totalmente e use o Single sozinho. Se a sua tarefa é "acessar esta página protegida a partir de um pool de IPs descartáveis sem ser sinalizado", combine-os. Eles não são alternativas. São etapas do mesmo fluxo de trabalho.
O que mudamos
A maior parte do ganho veio da reconstrução de três coisas no caminho de rotação de proxy. Nenhuma delas era uma ideia nova. Eram apenas coisas que estávamos adiando.
O pool parou de confiar em dados ruins. Antes da reconstrução, o diretório de proxies mantinha entradas por mais tempo do que deveria. Algumas dessas entradas não estavam mais acessíveis. Escolher uma delas significava que você passava de 15 a 30 segundos descobrindo da pior maneira. Mudamos para um modelo onde o pool reflete o que está realmente ativo em tempo quase real, e o picker prefere IPs que vimos ter sucesso recentemente.
Pontuações de qualidade por proxy, não apenas ativo-ou-inativo. Antes, um proxy que levava 5 segundos para responder parecia igual a um que levava 300 ms, desde que ambos eventualmente tivessem sucesso. Agora o picker também rastreia a latência. Proxies lentos, mas que funcionam, são empurrados para o final da fila. Os rápidos são reutilizados enquanto estão quentes. Isso importa mais do que parece, porque a cauda longa da distribuição de latência é composta principalmente por proxies lentos, mas que funcionam, que o antigo picker continuava escolhendo.
Pontuações de qualidade por destino. Um proxy que é confiável em um domínio pode ser instável em outro. Os IPs que funcionam perfeitamente contra um site são bloqueados ou sofrem rate limit em outro. Nosso picker agora rastreia o sucesso e a latência por host de destino, não apenas globalmente. Quando você solicita uma busca contra um domínio específico, escolhemos entre os proxies que realmente tiveram um bom desempenho nesse domínio recentemente. Proxies globalmente bons continuam na disputa, mas um proxy com um histórico forte no destino exato supera um com um histórico forte no geral.
Escalonamento de retry mais inteligente. Quando um request falhava, costumávamos disparar tentativas paralelas imediatamente. Isso era um desperdício e, pior, um único proxy ruim poderia desencadear uma cascata de acompanhamentos que falhavam um após o outro. Agora os retries escalam sequencialmente com backoffs curtos entre as tentativas, de modo que uma falha é uma falha e um retry é um retry, não um multiplicador.
Há uma segunda categoria de mudanças que vale a pena mencionar, embora seja menos visível para você.
Resiliência a reinicializações. Anteriormente, reimplantar qualquer parte da nossa infraestrutura de request significava uma janela de 5 a 15 minutos onde o mapa de pontuação de qualidade de proxy precisava se reconstruir do zero. Durante essa janela, o picker estava essencialmente adivinhando. Os clientes viam isso como um pico de latência logo após cada deploy. Agora nós persistimos esse mapa de qualidade entre as reinicializações. O sistema inicia aquecido. A partir de hoje, podemos implantar mudanças de infraestrutura no meio do dia sem causar picos de latência. O teste de reinicialização que executamos esta manhã mostrou uma oscilação de conexão de 15 segundos e zero tempo de recuperação depois disso. Essa é uma mudança silenciosa, mas significativa, no nosso ritmo de deploy: não precisamos mais agendar deploys em função do seu tráfego.
Sinais de falha mais limpos. Quando algo dentro da nossa infraestrutura dá errado, sua lógica de retry agora recebe o código de status HTTP correto para agir. Um backend brevemente indisponível retorna um 503. Um backend que retornou um JSON malformado retorna um 502. Um erro interno genuíno retorna um 500. Antes, todos os três pareciam 500s, o que significava que sua lógica de retry não conseguia distinguir "aguarde e tente novamente" de "isso está quebrado, escale". Agora ela consegue.
Como isso se parece para você
Se você está executando scrapers contra proxies rotacionados, a mudança prática é que seu p95 e p99 foram reduzidos aproximadamente pela metade em relação a uma semana atrás. O tempo médio de request diminui. Os retries devido a proxies lentos, mas que eventualmente funcionam, diminuem. A latência de cauda, que é o que faz um trabalho de 1.000 requests levar uma hora em vez de 20 minutos, cai junto.
Se você está executando o Single, verá o trabalho do picker dar resultados principalmente na cauda. O p99 caiu para menos de 600 ms, o que significa que até mesmo o seu 1% azarado de requests agora retorna rápido. O Single já era rápido. Agora ele é consistente.
Limitações honestas
Nós não corrigimos tudo. Alguns pontos específicos que ainda se aplicam:
O p99 do Proxy Finder ainda está em torno de 10 segundos. Nós o reduzimos pela metade, mas a cauda longa é real. Parte disso é nossa responsabilidade (profundidade do pool, ruído do picker em alvos raros). Grande parte não é: os sites de destino podem ser lentos por si só, podem aplicar rate limit em rotas específicas, podem exibir páginas de desafio que levam tempo para serem inspecionadas ou podem simplesmente sofrer timeout. Nossa infraestrutura pode escolher o melhor IP disponível, mas não pode acelerar um servidor de destino que está decidindo se vai responder. Se o seu trabalho depende de cada request retornar em menos de 5 segundos, defina um timeout por request que corresponda à sua tolerância e confie na camada de retry.
Alguns alvos são hostis, e isso aparece nos seus números. Como mencionado no início, a taxa de sucesso de 99,91% exclui um host que está nos desafiando ativamente esta semana. Incluí-lo reduz a taxa para cerca de 95%. Esse host não é o único. Qualquer agregador que trabalhe com dados da web pública vê isso. O alvo muda de semana para semana. A reconstrução do picker dá ao sistema uma chance muito melhor de contornar alvos hostis, mas não pode se sobrepor a um site que decidiu recusar o tráfego sumariamente. Nosso trabalho é fornecer a você os dados mais limpos possíveis nos casos cooperativos e falhar rapidamente nos hostis.
A comparação no mesmo dia tem ruído. A janela de 24 horas que estamos mostrando no gráfico de percentis compara ontem com o dia anterior. Efeitos do dia da semana, variação do site de destino e composição do pool mudam entre quaisquer duas janelas. Estamos confiantes na direção (o gráfico de 7 dias mostra um ponto de inflexão claro em 28 de abr), mas se você nos avaliar em relação à sua própria carga de trabalho, execute a comparação ao longo de pelo menos uma semana.
O que vem a seguir
A reescrita do picker é a base. Algumas coisas que temos na fila depois dela:
Um mapa de pontuação de qualidade compartilhado entre instâncias, para que aprendam umas com as outras em vez de construir mapas independentes. No momento, cada uma carrega sua própria visão de quais proxies são bons. Isso funciona, mas é um desperdício: cada instância paga o mesmo custo de aprendizado em paralelo.
Escolha baseada em confiança, onde preferimos proxies que realmente testamos nos últimos minutos em vez daqueles sobre os quais estamos adivinhando. Útil para clientes de baixo volume cujo tráfego não mantém o picker aquecido por si só.
E a longo prazo: transferir mais decisões para o picker para que a pontuação de qualidade por destino se torne um sinal entre muitos (perfil de latência do destino, padrões de hora do dia, integridade do segmento do pool). A infraestrutura agora existe para fazer isso sem desacelerar o caminho rápido.
O request mais barato é aquele em que não precisamos fazer retry. A reconstrução do picker é a aposta de que dados melhores no momento da escolha superam mais tentativas após o ocorrido. As primeiras 24 horas de evidências dizem que é a aposta certa.