4.2 millones de requests en 24 horas. Response promedio: 774 ms. Tasa de éxito: 99.91%. La misma carga de trabajo promedió 2.5 segundos durante los siete días anteriores a nuestra reconstrucción. Eso representa una caída del 70% en el tiempo de respuesta promedio, en el mismo hardware, contra los mismos sitios de destino y con el mismo pool de proxies. Reconstruimos las partes de la ruta de la request que silenciosamente les costaban las tardes a los clientes.
Este es un resumen de lo que cambió, cómo se ven realmente los números y por qué Single y Proxy Finder difieren por una razón.
Primero, una nota sobre los datos. Los números de este artículo provienen de tráfico de producción, excluyendo un host de destino específico. Ese host ha sido activamente hostil aplicando rate-limit y desafiando requests toda la semana, lo que sesga cada métrica que se analiza. Si se incluye, el éxito cae a aproximadamente el 95%. Pero esa brecha del 5% no se debe a un fallo de nuestra infraestructura. Es un sitio que rechaza las requests, independientemente de lo bueno que sea nuestro selector. Lo excluimos para que pueda ver lo que el sistema realmente hace en objetivos cooperativos.
Qué muestran los datos
Aquí está el promedio diario de nuestro tráfico de producción durante la última semana:
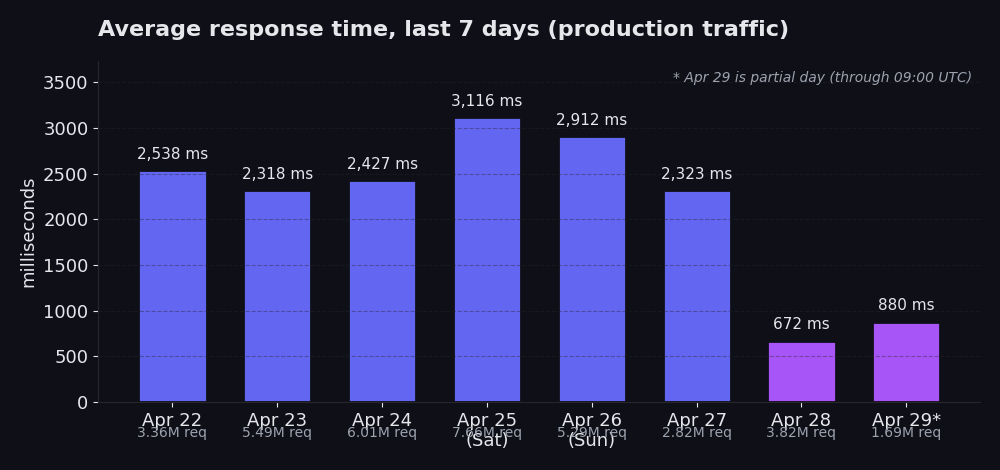
Del 22 al 27 de abril: promedios de entre 2,318 ms y 3,116 ms, tráfico de entre 2.8M y 7.7M de requests por día. El 25 de abril destaca con 3,116 ms en 7.7M de requests, que es el pico del sábado (el volumen del fin de semana es notablemente mayor y eleva el promedio). 28 de abril: 672 ms en 3.8M de requests. 29 de abril (día parcial, hasta las 09:00 UTC): 880 ms en 1.7M de requests hasta el momento.
Misma arquitectura. Mismos proxies. Mismos sitios de destino. Diferente ruta de la request.
El panorama de los percentiles es más claro que el del promedio. Los promedios pueden ocultar colas desfavorables. Los percentiles no.
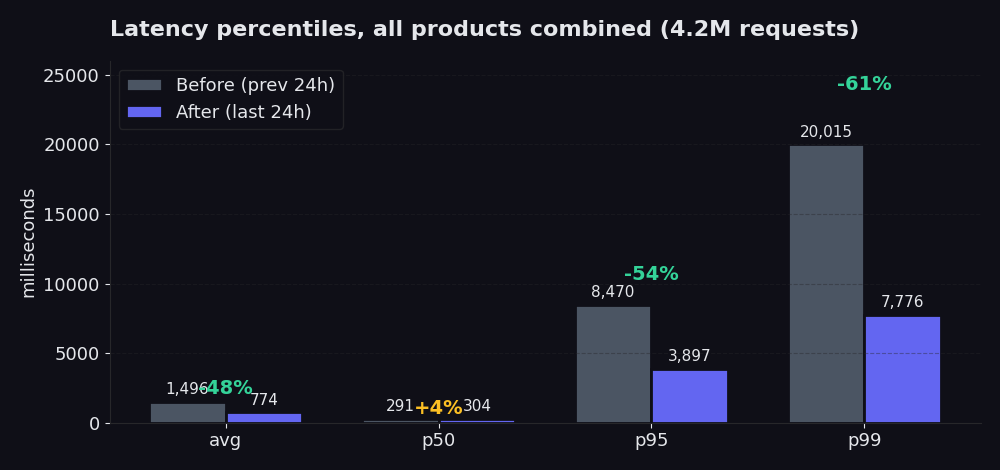
El gráfico compara las 24 horas posteriores a nuestra reconstrucción con las 24 horas anteriores. El p50 apenas se movió (y subió un 4%, lo cual son datos honestos; la ruta rápida ya estaba bien y el nuevo selector dedica un poco más de esfuerzo al principio para ahorrar mucho en la cola). El promedio cayó un 48% en esa ventana. El p95 pasó de 8.5 segundos a 3.9 segundos, una reducción del 54%. El p99 pasó de 20 segundos a 7.8 segundos, una reducción del 61%. Ahí es donde radica el problema, y eso es lo que realmente se siente cuando su scraper está esperando a que regrese el 5% más lento de las requests. En comparación con los siete días anteriores a la reconstrucción (donde el promedio se mantuvo en torno a los 2.5 segundos), el promedio actual de 774 ms representa una caída del 70%.
La tasa de éxito también subió: del 98.85% al 99.91% en la misma ventana. Específicamente en Proxy Finder, la tasa alcanzó el 99.89%. En Single, el 99.96%. Ese es el número del que estamos más orgullosos, porque indica con qué frecuencia entregamos datos útiles en el primer intento sin tener que reintentar.
Dos productos, dos perfiles de latencia
No comparamos Single y Proxy Finder entre sí. Resuelven problemas diferentes y tienen presupuestos de latencia distintos. Si está usando uno y mirando el número del otro, está viendo el marcador equivocado.
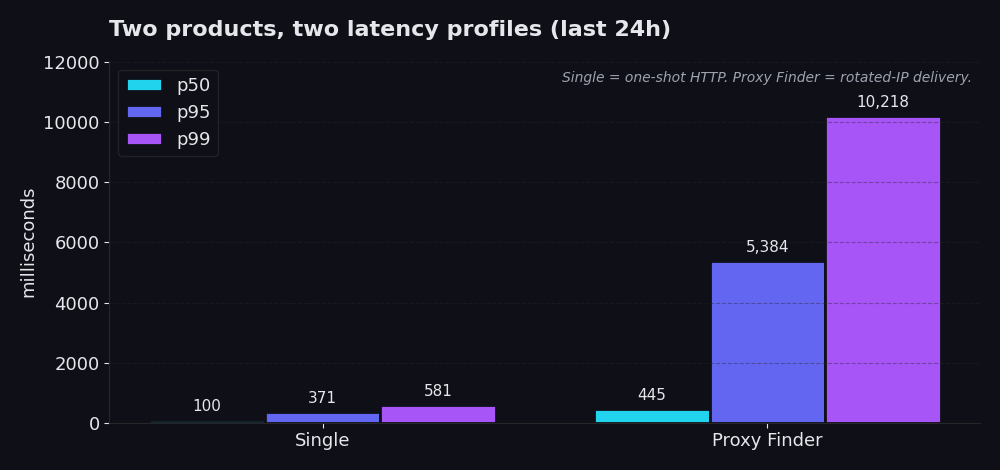
Single es una request HTTP de un solo intento a través de nuestra infraestructura. Usted nos proporciona una URL y, en aproximadamente el 99% de las llamadas de producción reales, un proxy id que ya sabe que funciona. Obtenemos la URL a través de ese proxy y usted recibe la response. Sin lógica de rotación, sin cascada de reintentos, sin rotación constante de proxies. Últimas 24 horas: p50 de 100 ms, p95 de 371 ms, p99 de 581 ms. La mayoría de las llamadas finalizan en menos de una quinta parte de un segundo. Incluso el peor 1% regresa en menos de 600 ms.
Proxy Finder es la capa de descubrimiento. Rota su request a través de un pool de proxies públicos, valida cada candidato, reintenta en caso de fallo y devuelve la primera response que realmente funcionó, además del ID del proxy que lo logró. p50 de 445 ms, p95 de 5.4 segundos, p99 de 10.2 segundos. Más lento porque tiene que serlo. El objetivo principal es que la IP con la que su scraper accede al sitio de destino sea rotativa, temporal y desechable. Está intercambiando unos segundos de sobrecarga por resiliencia contra listas de bloqueo y rate limits.
La razón por la que Single es tan rápido no es magia. Es que Single confía en algo que Proxy Finder tuvo que descubrir. Cuando llama a Proxy Finder una vez y devuelve "este proxy funcionó, aquí está su ID", las búsquedas posteriores contra el mismo objetivo a través de Single omiten todo el paso de descubrimiento. Va directamente al proxy que ya pasó la validación.
Cómo los usan los equipos en conjunto
La mayoría de los equipos que acceden a un objetivo con frecuencia siguen un patrón de dos pasos. La primera llamada es exploratoria; las demás son definitivas.
La primera llamada va a Proxy Finder. Rota a través del pool, valida cada candidato según sus reglas de aceptación y devuelve la response junto con el ID del proxy que funcionó. Ese ID es su referencia para cualquier llamada futura que quiera acceder al mismo objetivo.
Cada llamada posterior va a Single, con el ID de proxy adjunto. Sin descubrimiento, sin validación, sin cascada de reintentos. Enrutamos su request a través del proxy que especificó y transmitimos la response de vuelta. Esa es la ruta que alcanza los 100 ms en el p50.
Cuando el proxy que funcionó ayer se bloquea hoy, se recurre a Proxy Finder para una llamada de redescubrimiento, y luego se reanudan las búsquedas de Single con el nuevo ID. No encubrimos la obsolescencia. Si un ID de proxy que nos proporcionó está inactivo, se lo informamos rápidamente para que pueda rotarlo.
La división 99/1 (Single dominante en volumen, Proxy Finder dominante en descubrimiento) es la razón por la que nuestros números de Single se ven así. No es que Single sea intrínsecamente un producto más rápido. Es que Single es el estado estable y Proxy Finder es el paso de calibración. La mayoría de las cargas de trabajo se encuentran principalmente en estado estable.
Si su tarea es "obtener este JSON de una API pública limpia a la que no le importa quién llama", omita el proxy por completo y use Single por sí solo. Si su tarea es "acceder a esta página protegida desde un pool de IPs desechables sin ser detectado", combínelos. No son alternativas. Son etapas del mismo flujo de trabajo.
Qué cambiamos
La mayor parte del éxito provino de reconstruir tres cosas en la ruta de rotación de proxies. Ninguna de ellas era una idea nueva. Eran simplemente cosas que habíamos estado posponiendo.
El pool dejó de confiar en datos incorrectos. Antes de la reconstrucción, el directorio de proxies conservaba las entradas más tiempo del debido. Algunas de esas entradas ya no eran accesibles. Elegir una de ellas significaba pasar de 15 a 30 segundos descubriendo el problema de la manera difícil. Pasamos a un modelo en el que el pool refleja lo que realmente está activo casi en tiempo real, y el selector prefiere las IPs que hemos visto funcionar correctamente de forma reciente.
Puntuaciones de calidad por proxy, no solo de funcionamiento o caída. Antes, un proxy que tardaba 5 segundos en responder se veía igual que uno que tardaba 300 ms, siempre que ambos tuvieran éxito eventualmente. Ahora el selector también realiza un seguimiento de la latencia. Los proxies lentos pero que funcionan se desplazan hacia abajo en la cola. Los rápidos se reutilizan mientras están activos. Esto importa más de lo que parece, porque la cola larga de la distribución de latencia está compuesta principalmente por proxies lentos pero que funcionan que el selector anterior seguía eligiendo.
Puntuaciones de calidad por objetivo. Un proxy que es confiable en un dominio puede ser inestable en otro. Las IPs que funcionan limpiamente contra un sitio se bloquean o sufren rate-limit en otro. Nuestro selector ahora realiza un seguimiento del éxito y la latencia por host de destino, no solo de forma global. Cuando solicita una búsqueda contra un dominio específico, elegimos entre los proxies que realmente han tenido un buen desempeño en ese dominio recientemente. Los proxies que son buenos a nivel global siguen compitiendo, pero un proxy con un historial sólido en el objetivo exacto supera a uno con un historial sólido en general.
Escalada de reintentos más inteligente. Cuando una request fallaba, solíamos lanzar intentos paralelos de inmediato. Eso era ineficiente y, lo que es peor, un solo proxy defectuoso podía desencadenar una cascada de seguimientos que a su vez fallaban todos. Ahora los reintentos escalan secuencialmente con breves tiempos de espera (backoffs) entre intentos, de modo que un fallo es un fallo y un reintento es un reintento, no un multiplicador.
Hay una segunda categoría de cambios que vale la pena mencionar, aunque sea menos visible para usted.
Resiliencia ante reinicios. Anteriormente, volver a desplegar cualquiera de nuestras infraestructuras de request implicaba una ventana de 5 a 15 minutos en la que el mapa de puntuación de calidad de los proxies tenía que reconstruirse desde cero. Durante esa ventana, el selector básicamente estaba adivinando. Los clientes lo percibían como un pico de latencia justo después de cada despliegue. Ahora persistimos ese mapa de calidad a través de los reinicios. El sistema arranca caliente. A partir de hoy, podemos desplegar cambios de infraestructura a mitad del día sin generarle un pico de latencia. La prueba de reinicio que ejecutamos esta mañana mostró una interrupción de conexión de 15 segundos y cero tiempo de recuperación posterior. Ese es un cambio silencioso pero significativo en nuestra cadencia de despliegue: ya no tenemos que programar los redespliegues en función de su tráfico.
Señales de fallo más claras. Cuando algo sale mal dentro de nuestra infraestructura, su lógica de reintento ahora recibe el código de estado HTTP correcto para actuar. Un backend que no está disponible brevemente devuelve un 503. Un backend que devolvió un JSON malformado devuelve un 502. Un error interno real devuelve un 500. Antes, los tres se veían como 500, lo que significaba que su lógica de reintento no podía distinguir entre "espere e intente de nuevo" y "esto está roto, escale". Ahora sí puede.
Qué significa esto para usted
Si está ejecutando scrapers contra proxies rotativos, el cambio práctico es que su p95 y p99 se reducen aproximadamente a la mitad en comparación con hace una semana. El tiempo promedio de la request disminuye. Los reintentos debido a proxies lentos pero que finalmente funcionan disminuyen. La latencia de cola, que es lo que hace que una tarea de 1,000 requests tarde una hora en lugar de 20 minutos, disminuye con ella.
Si está ejecutando Single, verá que el trabajo del selector da sus frutos principalmente en la cola. El p99 cayó a menos de 600 ms, lo que significa que incluso su 1% desafortunado de las requests ahora regresa rápido. Single ya era rápido. Ahora es consistente.
Limitaciones honestas
No lo solucionamos todo. Algunos detalles específicos que aún se aplican:
El p99 de Proxy Finder sigue rondando los 10 segundos. Lo redujimos a la mitad, pero la cola larga es real. Parte de eso es responsabilidad nuestra (profundidad del pool, ruido del selector en objetivos poco comunes). Gran parte no lo es: los sitios de destino pueden ser lentos por sí mismos, pueden aplicar rate-limit a rutas específicas, pueden mostrar páginas de desafío que toman tiempo inspeccionar o simplemente pueden agotar el tiempo de espera (timeout). Nuestra infraestructura puede elegir la mejor IP disponible, pero no puede acelerar un servidor de destino que está decidiendo si responder. Si su tarea depende de que cada request regrese en menos de 5 segundos, configure un timeout por request que se ajuste a su tolerancia y confíe en la capa de reintentos.
Algunos objetivos son hostiles, y eso se refleja en sus números. Como se mencionó al principio, la tasa de éxito del 99.91% excluye un host que nos está desafiando activamente esta semana. Si se incluye, la tasa cae a aproximadamente el 95%. Ese host no es el único. Cualquier agregador que trabaje con datos de la web pública experimenta esto. El objetivo cambia de una semana a otra. La reconstrucción del selector le da al sistema una oportunidad mucho mejor de esquivar objetivos hostiles, pero no puede anular un sitio que ha decidido rechazar el tráfico por completo. Nuestro trabajo es ofrecerle los datos más limpios posibles en los casos cooperativos y fallar rápidamente en los hostiles.
La comparación del mismo día presenta ruido. La ventana de 24 horas que mostramos en el gráfico de percentiles compara el día de ayer con el anterior. Los efectos del día de la semana, la variación del sitio de destino y la composición del pool cambian entre dos ventanas cualesquiera. Confiamos en la dirección (el gráfico de 7 días muestra un punto de inflexión claro el 28 de abril), pero si nos compara con su propia carga de trabajo, realice la comparación durante al menos una semana.
Qué sigue
La reescritura del selector es la base. Algunas cosas que tenemos en cola detrás de ella:
Un mapa de puntuación de calidad compartido entre instancias, para que aprendan unas de otras en lugar de construir mapas independientes. En este momento, cada una tiene su propia imagen de qué proxies son buenos. Eso funciona, pero es ineficiente: cada instancia paga el mismo costo de aprendizaje en paralelo.
Selección basada en confianza, donde preferimos proxies que realmente hayamos probado en los últimos minutos en lugar de aquellos sobre los que estamos adivinando. Útil para clientes de bajo volumen cuyo tráfico no mantiene el selector caliente por sí solo.
Y a más largo plazo: trasladar más decisiones al selector para que la puntuación de calidad por objetivo se convierta en una señal entre muchas (perfil de latencia del objetivo, patrones de la hora del día, salud del segmento del pool). La infraestructura ahora existe para hacer esto sin ralentizar la ruta rápida.
La request más barata es la que no tuvimos que reintentar. La reconstrucción del selector es la apuesta de que mejores datos al momento de elegir superan a más intentos a posteriori. Las primeras 24 horas de evidencia indican que es la apuesta correcta.