4,2 miliona requestów w 24 godziny. Średnia odpowiedź: 774 ms. Success rate: 99,91%. To samo obciążenie generowało średnio 2,5 sekundy przez siedem dni przed naszą przebudową. To 70% spadek średniego czasu odpowiedzi, na tym samym sprzęcie, dla tych samych stron docelowych, z tą samą pulą proxy. Przebudowaliśmy te części ścieżki requestu, które po cichu kosztowały naszych klientów wolne wieczory.
To podsumowanie tego, co się zmieniło, jak naprawdę wyglądają liczby i dlaczego Single oraz Proxy Finder różnią się od siebie nie bez powodu.
Najpierw krótka uwaga o danych. Liczby w tym poście pochodzą z ruchu produkcyjnego, z wyłączeniem jednego konkretnego hosta docelowego. Ten host przez cały tydzień aktywnie nakładał rate limit i blokował requesty, co zaburza każdą metrykę. Po jego uwzględnieniu success rate spada do około 95%. Jednak ta 5% różnica to nie awaria naszej infrastruktury. To po prostu jedna witryna odrzucająca requesty, bez względu na to, jak dobry jest nasz picker. Wykluczyliśmy ją, aby pokazać, jak system radzi sobie z celami, które współpracują.
Co pokazują dane
Oto dzienna średnia dla naszego ruchu produkcyjnego z ostatniego tygodnia:
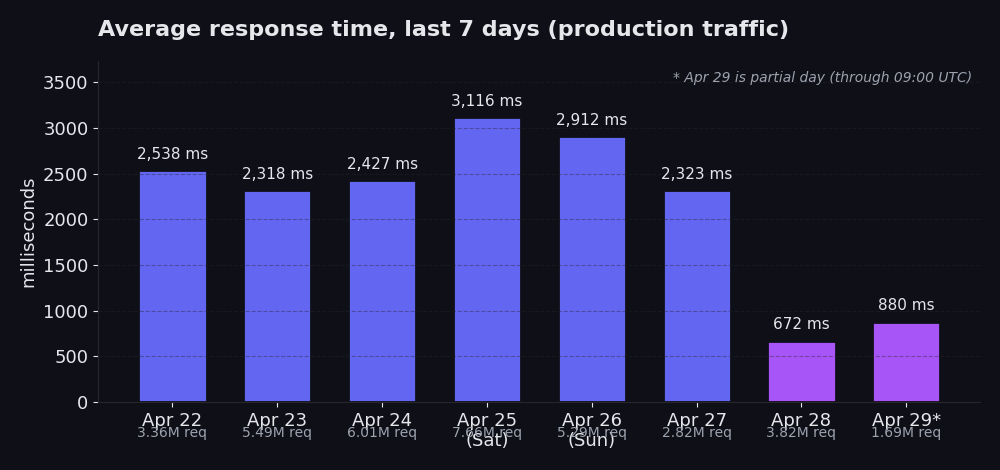
Od 22 do 27 kwietnia: średnie między 2318 ms a 3116 ms, ruch od 2,8 mln do 7,7 mln requestów dziennie. 25 kwietnia wyróżnia się wynikiem 3116 ms przy 7,7 mln requestów, co stanowi sobotni szczyt (wolumen weekendowy jest wyraźnie wyższy i zawyża średnią). 28 kwietnia: 672 ms przy 3,8 mln requestów. 29 kwietnia (częściowy dzień, do 09:00 UTC): jak dotąd 880 ms przy 1,7 mln requestów.
Ta sama architektura. Te same proxy. Te same strony docelowe. Inna ścieżka requestu.
Obraz percentyli jest wyraźniejszy niż średnia. Średnie mogą ukrywać anomalie na krańcach rozkładu. Percentyle tego nie robią.
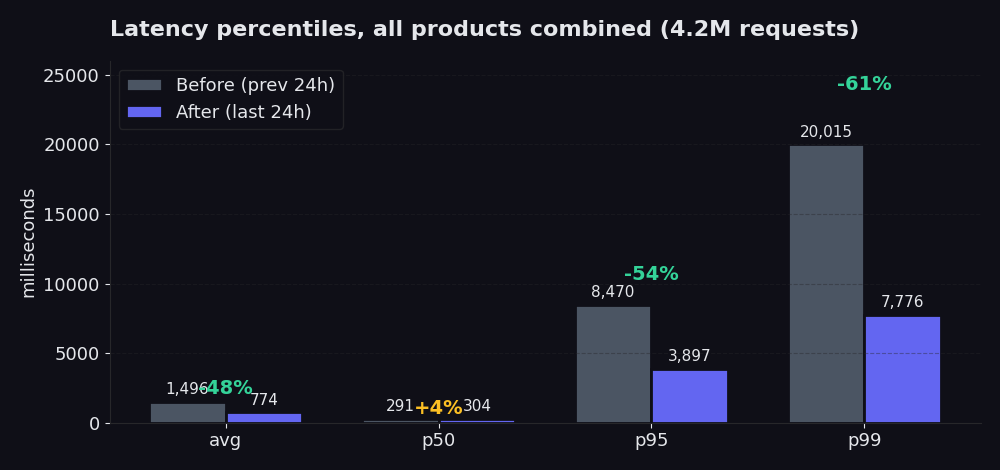
Wykres porównuje 24 godziny po naszej przebudowie z 24 godzinami przed nią. p50 ledwo się zmienił (wzrósł o 4%, co jest uczciwym wynikiem; szybka ścieżka działała już dobrze, a nowy picker wkłada nieco więcej wysiłku na starcie, aby zaoszczędzić sporo na samym końcu). Średnia spadła o 48% w tym oknie. p95 spadł z 8,5 sekundy do 3,9 sekundy, co oznacza redukcję o 54%. p99 spadł z 20 sekund do 7,8 sekundy, czyli o 61%. To tam kryje się największy problem i to właśnie odczuwasz, gdy twój scraper czeka na powrót najwolniejszych 5% requestów. W porównaniu z siedmioma dniami przed przebudową (gdzie średnia utrzymywała się na poziomie około 2,5 sekundy), dzisiejsza średnia 774 ms to spadek o 70%.
Success rate również wzrósł: z 98,85% do 99,91% w tym samym oknie. W przypadku samego Proxy Finder wskaźnik ten osiągnął 99,89%. Dla Single wyniósł 99,96%. To wynik, z którego jesteśmy najbardziej dumni, ponieważ pokazuje, jak często zwracamy przydatne dane już przy pierwszej próbie, bez konieczności ponawiania (retry).
Dwa produkty, dwa profile opóźnień
Nie porównujemy Single i Proxy Finder ze sobą. Rozwiązują inne problemy i mają różne budżety opóźnień. Jeśli używasz jednego, a patrzysz na liczby drugiego, patrzysz na niewłaściwą tablicę wyników.
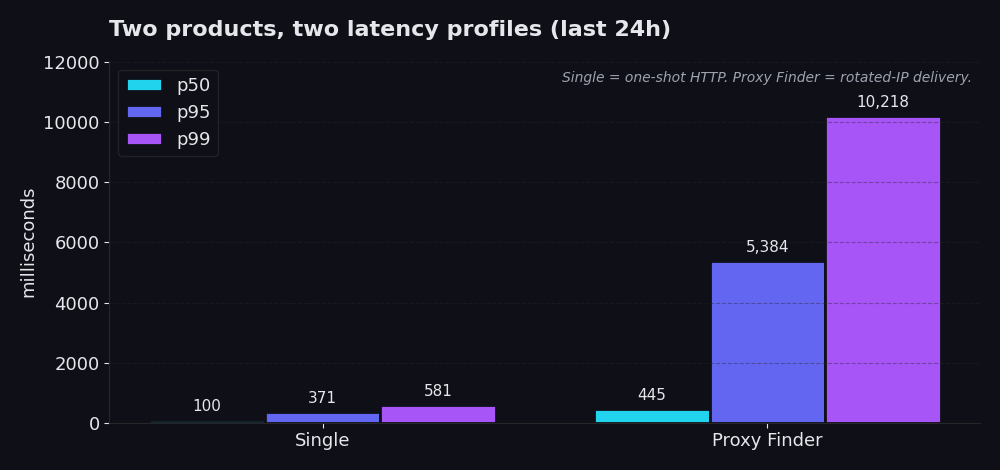
Single to pojedynczy request HTTP przechodzący przez naszą infrastrukturę. Podajesz nam URL i, w około 99% rzeczywistych wywołań produkcyjnych, id proxy, o którym wiesz, że działa. Pobieramy URL przez to proxy, a ty otrzymujesz response. Bez logiki rotacji, bez kaskady retry, bez rotacji proxy. Ostatnie 24 godziny: p50 na poziomie 100 ms, p95 na poziomie 371 ms, p99 na poziomie 581 ms. Większość wywołań kończy się w czasie krótszym niż jedna piąta sekundy. Nawet najgorsze 1% wraca w czasie poniżej 600 ms.
Proxy Finder to warstwa wyszukiwania (discovery). Rotuje twój request w puli publicznych proxy, waliduje każdego kandydata, ponawia próby w razie niepowodzenia i zwraca pierwszy response, który zadziałał, wraz z id proxy, które go obsłużyło. p50 na poziomie 445 ms, p95 na poziomie 5,4 sekundy, p99 na poziomie 10,2 sekundy. Wolniej, bo tak musi być. Cały sens polega na tym, że IP, z którego twój scraper uderza w stronę docelową, jest rotowane i jednorazowe. Wymieniasz kilka sekund narzutu na odporność przeciwko listom blokad i rate limitom.
Powód, dla którego Single jest tak szybki, to nie magia. Single ufa temu, co Proxy Finder musiał dopiero odkryć. Gdy wywołasz Proxy Finder raz, a on zwróci komunikat „to proxy zadziałało, oto jego id”, kolejne pobrania tego samego celu przez Single pomijają cały krok wyszukiwania. Trafiasz bezpośrednio do proxy, które przeszło już walidację.
Jak zespoły używają ich razem
Większość zespołów często odpytujących dany cel stosuje dwuetapowy schemat. Pierwsze wywołanie ma charakter badawczy, kolejne są już docelowe.
Pierwsze wywołanie trafia do Proxy Finder. Rotuje on zapytania w puli, waliduje każdego kandydata pod kątem twoich reguul akceptacji i zwraca response wraz z id proxy, które zadziałało. To id staje się twoim identyfikatorem dla każdego kolejnego wywołania tego samego celu.
Każde kolejne wywołanie trafia do Single z dołączonym id proxy. Bez wyszukiwania, bez walidacji, bez kaskady retry. Kierujemy twój request przez wskazane proxy i przesyłamy response z powrotem. To jest właśnie ścieżka, która osiąga 100 ms przy p50.
Gdy proxy, które działało wczoraj, zostanie zablokowane dzisiaj, wracasz do Proxy Finder na jedno wywołanie, aby znaleźć nowe, a następnie wznawiasz pobieranie przez Single z nowym id. Nie ukrywamy nieaktualnych danych. Jeśli przekazane id proxy jest martwe, szybko cię o tym informujemy, abyś mógł dokonać rotacji.
Podział 99/1 (Single dominuje wolumenem, Proxy Finder dominuje w wyszukiwaniu) to powód, dla którego statystyki Single wyglądają tak dobrze. Nie chodzi o to, że Single jest sam z siebie szybszym produktem. Single to stan stabilny, a Proxy Finder to krok kalibracji. Większość zadań przez większość czasu działa w stanie stabilnym.
Jeśli twoim zadaniem jest „pobierz ten JSON z czystego publicznego API, które nie dba o to, kto pyta”, pomiń proxy całkowicie i użyj samego Single. Jeśli twoim zadaniem jest „wejdź na tę zabezpieczoną stronę z puli jednorazowych adresów IP bez wykrycia”, połącz je. To nie są alternatywy. To etapy tego samego workflow.
Co zmieniliśmy
Większość zysku przyniosła przebudowa trzech elementów w ścieżce rotacji proxy. Żaden z nich nie był nowym pomysłem. To były po prostu rzeczy, które odkładaliśmy na później.
Pula przestała ufać błędnym danym. Przed przebudową katalog proxy przechowywał wpisy dłużej niż powinien. Część z nich była już nieosiągalna. Wybranie jednego z nich oznaczało stratę od 15 do 30 sekund na bolesne przekonanie się o tym. Przeszliśmy na model, w którym pula odzwierciedla to, co faktycznie działa w czasie zbliżonym do rzeczywistego, a picker preferuje adresy IP, które ostatnio odniosły sukces.
Wskaźniki jakości (quality scores) dla każdego proxy, a nie tylko zero-jedynkowy status. Wcześniej proxy, które odpowiadało 5 sekund, wyglądało tak samo jak to, które potrzebowało 300 ms, o ile oba ostatecznie zwracały sukces. Teraz picker śledzi również opóźnienia. Wolne, ale działające proxy są spychane na koniec kolejki. Szybkie są używane ponownie, dopóki są aktywne. To ma większe znaczenie, niż się wydaje, ponieważ długi ogon rozkładu opóźnień to głównie wolne, ale działające proxy, które stary picker ciągle wybierał.
Wskaźniki jakości per target. Proxy, które jest niezawodne na jednej domenie, może działać niestabilnie na innej. Adresy IP, które działają bezproblemowo na jednej stronie, na innej mogą być blokowane lub objęte rate limitem. Nasz picker śledzi teraz sukcesy i opóźnienia dla każdego hosta docelowego, a nie tylko globalnie. Gdy zlecasz pobranie z konkretnej domeny, wybieramy spośród proxy, które ostatnio dobrze radziły sobie z tą domeną. Globalnie dobre proxy nadal biorą udział w grze, ale proxy z doskonałą historią na konkretnym celu ma pierwszeństwo przed tym, które ma dobre wyniki ogólne.
Sprytniejsza eskalacja retry. Gdy request kończy się niepowodzeniem, dawniej natychmiast uruchamialiśmy równoległe próby. Było to marnotrawstwo, a co gorsza, jedno złe proxy mogło wywołać kaskadę kolejnych prób, które również kończyły się fiaskiem. Teraz retry eskalują sekwencyjnie z krótkimi przerwami (backoff) między próbami, więc błąd to błąd, a retry to retry, a nie mnożnik problemów.
Istnieje druga kategoria zmian warta odnotowania, nawet jeśli jest dla ciebie mniej widoczna.
Odporność na restarty. Wcześniej ponowne wdrożenie (redeploy) dowolnego elementu naszej infrastruktury requestów oznaczało od 5 do 15 minut okna, w którym mapa jakości proxy musiała budować się od zera. W tym czasie picker w zasadzie zgadywał. Klienci widzieli to jako skok opóźnień tuż po każdym wdrożeniu. Teraz zapisujemy tę mapę jakości między restartami. System wstaje od razu rozgrzany. Od dziś możemy wdrażać zmiany w infrastrukturze w środku dnia, nie powodując skoków opóźnień. Test restartu, który przeprowadziliśmy dziś rano, wykazał 15-sekundowe zakłócenie połączenia i zerowy czas powrotu do normy. To cicha, ale znacząca zmiana w naszym cyklu wdrożeń: nie musimy już planować redeployów pod kątem twojego ruchu.
Czytelniejsze sygnały błędów. Gdy coś pójdzie nie tak wewnątrz naszej infrastruktury, twoja logika retry otrzymuje teraz właściwy kod statusu HTTP, na podstawie którego może podjąć działanie. Backend, który jest chwilowo niedostępny, zwraca 503. Backend, który zwrócił uszkodzony JSON, zwraca 502. Rzeczywisty błąd wewnętrzny zwraca 500. Wcześniej wszystkie trzy wyglądały jak 500, co oznaczało, że twoja logika retry nie potrafiła odróżnić „poczekaj i spróbuj ponownie” od „to jest zepsute, eskaluj”. Teraz już potrafi.
Co to oznacza dla ciebie
Jeśli uruchamiasz scrapery korzystające z rotowanych proxy, praktyczna zmiana polega na tym, że twoje p95 i p99 zostały skrócone o około połowę w porównaniu z zeszłym tygodniem. Średni czas requestu spada. Liczba retry spowodowanych przez wolne, ale ostatecznie działające proxy maleje. Opóźnienie ogona (tail latency), czyli to, co sprawia, że zadanie na 1000 requestów trwa godzinę zamiast 20 minut, spada wraz z nim.
Jeśli korzystasz z Single, zobaczysz, że praca nad pickerem opłaciła się głównie na samym końcu rozkładu. p99 spadł poniżej 600 ms, co oznacza, że nawet twój pechowy 1% requestów wraca teraz szybko. Single był już szybki. Teraz jest stabilny.
Uczciwe ograniczenia
Nie naprawiliśmy wszystkiego. Kilka szczegółów, które nadal obowiązują:
p99 dla Proxy Finder nadal wynosi około 10 sekund. Skróciliśmy ten czas o połowę, ale długi ogon to rzeczywistość. Część z tego leży po naszej stronie (głębokość puli, szum pickera na rzadkich celach). Duża część jednak nie: strony docelowe mogą być same w sobie wolne, mogą nakładać rate limit na określone ścieżki, serwować strony z wyzwaniami (challenges), których analiza wymaga czasu, lub po prostu zgłaszać timeout. Nasza infrastruktura może wybrać najlepsze dostępne IP, ale nie przyspieszy serwera docelowego, który dopiero decyduje, czy odpowiedzieć. Jeśli twoje zadanie wymaga, aby każdy request wracał w czasie poniżej 5 sekund, ustaw timeout na pojedynczy request dopasowany do twojej tolerancji i zaufaj warstwie retry.
Niektóre cele są wrogie i to widać w twoich statystykach. Jak wspomnieliśmy na początku, success rate na poziomie 99,91% wyklucza jednego hosta, który aktywnie nas blokuje w tym tygodniu. Uwzględnienie go obniża wskaźnik do około 95%. Ten host nie jest wyjątkowy. Każdy agregator pracujący z danymi z publicznego internetu to widzi. Cel zmienia się z tygodnia na tydzień. Przebudowa pickera daje systemowi znacznie większe szanse na omijanie wrogich celów, ale nie zmusi do współpracy witryny, która zdecydowała się całkowicie odrzucać ruch. Naszym zadaniem jest dostarczenie jak najczystszych danych w przypadkach, gdy cel współpracuje, oraz szybkie zgłaszanie błędów w tych wrogich.
Porównanie z tego samego dnia zawiera szum. Pokazywane przez nas 24-godzinne okno na wykresie percentyli porównuje wczorajszy dzień z przedwczorajszym. Efekty dnia tygodnia, zmienność stron docelowych i skład puli zmieniają się między dowolnymi dwoma oknami. Jesteśmy pewni kierunku zmian (wykres 7-dniowy pokazuje wyraźny punkt zwrotny 28 kwietnia), ale jeśli porównujesz nas ze swoim własnym obciążeniem roboczym, przeprowadź testy przez co najmniej tydzień.
Co dalej
Przepisanie pickera to fundament. Kilka rzeczy, które mamy w kolejce tuż za nim:
Współdzielona mapa wskaźników jakości między instancjami, aby uczyły się od siebie nawzajem zamiast budować niezależne mapy. Obecnie każda z nich ma własny obraz tego, które proxy są dobre. To działa, ale jest nieefektywne: każda instancja ponosi ten sam koszt uczenia się równolegle.
Wybór oparty na zaufaniu (confidence-based picking), w którym preferujemy proxy faktycznie przetestowane w ciągu ostatnich kilku minut zamiast tych, o których tylko wnioskujemy. Przydatne dla klientów o mniejszym wolumenie ruchu, którego intensywność nie wystarcza do samodzielnego utrzymania pickera w stanie rozgrzanym.
I w dłuższej perspektywie: przeniesienie większej liczby decyzji do pickera, aby wskaźnik jakości per target stał się jednym z wielu sygnałów (profil opóźnień celu, wzorce pory dnia, kondycja segmentu puli). Infrastruktura pozwala już na to bez spowalniania hot path.
Najtańszy request to ten, którego nie musieliśmy ponawiać. Przebudowa pickera to zakład o to, że lepsze dane w momencie wyboru są lepsze niż więcej prób po fakcie. Pierwsze 24 godziny dowodzą, że to właściwy zakład.