4,2 миллиона запросов за 24 часа. Среднее время response: 774 мс. Success rate: 99,91%. Тот же объем нагрузки в среднем занимал 2,5 секунды в течение семи дней до нашего обновления. Это 70% падение среднего времени response на том же оборудовании, для тех же целевых сайтов и с тем же proxy-пулом. Мы перестроили части request path, которые незаметно лишали клиентов свободного времени по вечерам.
В этой статье мы описываем, что изменилось, как цифры выглядят на самом деле и почему Single и Proxy Finder различаются по вполне конкретным причинам.
Сначала небольшое примечание о данных. Цифры в этом посте получены из реального трафика (production traffic), за исключением одного конкретного целевого хоста. Этот хост активно применял rate limit и выдавал проверки на каждый request всю неделю, что искажает любые метрики. Если включить его, показатель успеха падает примерно до 95%. Но этот разрыв в 5% не означает сбой нашей инфраструктуры. Это просто один сайт, который отклоняет requests, независимо от того, насколько хорош наш picker. Мы исключили его, чтобы вы могли увидеть, как система работает с более лояльными целями.
Что показывают данные
Вот среднесуточные показатели нашего production-трафика за последнюю неделю:
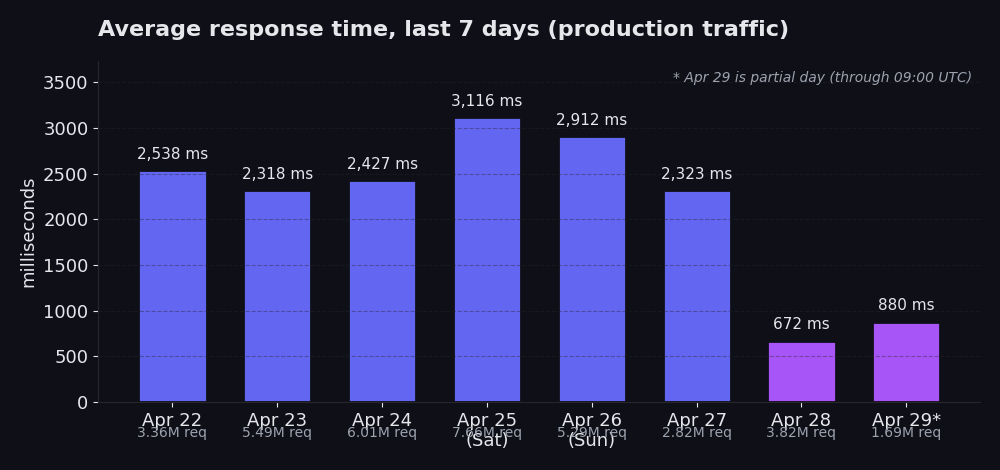
С 22 по 27 апреля: средние значения от 2 318 мс до 3 116 мс, трафик от 2,8 млн до 7,7 млн requests в день. 25 апреля выделяется показателем 3 116 мс при 7,7 млн requests, это субботний пик (объем трафика в выходные заметно выше, что увеличивает среднее значение). 28 апреля: 672 мс при 3,8 млн requests. 29 апреля (неполный день, до 09:00 UTC): 880 мс при 1,7 млн requests на данный момент.
Та же архитектура. Те же proxies. Те же целевые сайты. Другой request path.
Картина с перцентилями выглядит более четкой, чем со средними значениями. Средние показатели могут скрывать длинные хвосты распределения. Перцентили этого не делают.
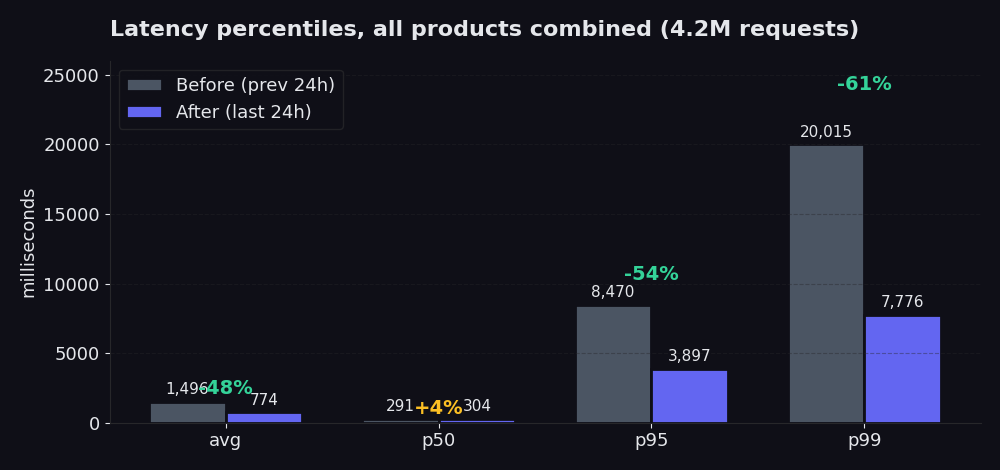
На графике сравниваются 24 часа после нашего обновления с 24 часами до него. p50 практически не изменился (и даже вырос на 4%, и это честные данные, быстрый путь и так работал отлично, а новый picker тратит чуть больше усердия на старте, чтобы сэкономить массу времени на хвосте распределения). Среднее значение за этот период снизилось на 48%. p95 снизился с 8,5 до 3,9 секунд, то есть на 54%. p99 снизился с 20 до 7,8 секунд, то есть на 61%. Именно здесь кроется основная проблема, и именно это вы ощущаете, когда ваш scraper ждет возврата самых медленных 5% requests. По сравнению с семью днями до обновления (когда среднее значение держалось на уровне 2,5 секунд), сегодняшнее среднее значение в 774 мс представляет собой падение на 70%.
Success rate также вырос: с 98,85% до 99,91% за тот же период. В частности, для Proxy Finder этот показатель достиг 99,89%. Для Single он составил 99,96%. Это цифра, которой мы гордимся больше всего, поскольку она показывает, как часто мы возвращаем полезные данные с первой попытки без необходимости повторных запросов.
Два продукта, два профиля задержки
Мы не сравниваем Single и Proxy Finder друг с другом. Они решают разные задачи, и у них разные бюджеты задержки. Если вы используете один продукт, а смотрите на показатели другого, вы ориентируетесь не на то табло.
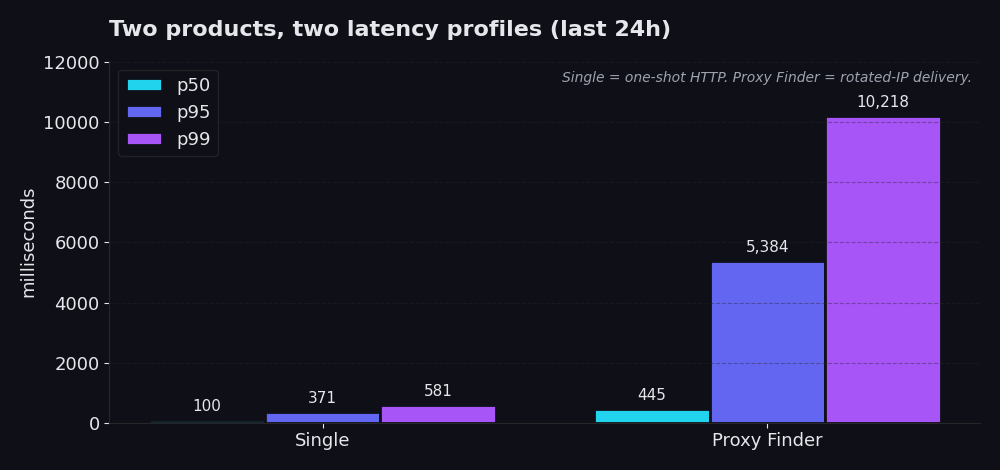
Single представляет собой разовый HTTP-request через нашу инфраструктуру. Вы передаете нам URL и, примерно в 99% реальных production-вызовов, уже известный вам рабочий proxy id. Мы запрашиваем URL через этот proxy, а вы получаете response. Никакой логики ротации, никаких каскадных повторных попыток, никакой смены proxy. За последние 24 часа: p50 составляет 100 мс, p95 составляет 371 мс, p99 составляет 581 мс. Большинство вызовов завершаются менее чем за одну пятую секунды. Даже худший 1% возвращается менее чем за 600 мс.
Proxy Finder представляет собой уровень обнаружения. Он ротирует ваш request по пулу публичных proxies, проверяет каждого кандидата, выполняет повторные попытки при сбое и возвращает первый успешно сработавший response, а также id выполнившего его proxy. p50 составляет 445 мс, p95 составляет 5,4 секунды, p99 составляет 10,2 секунды. Это работает медленнее, потому что так и должно быть. Весь смысл в том, что IP-адрес, с которого ваш scraper обращается к целевому сайту, является ротируемым, временным и одноразовым. Вы меняете несколько секунд накладных расходов на устойчивость к блокировкам и rate limits.
Причина высокой скорости Single кроется не в магии. Дело в том, что Single доверяет данным, которые Proxy Finder пришлось собирать. Когда вы один раз вызываете Proxy Finder и он возвращает сообщение вида "этот proxy сработал, вот его id", последующие запросы к той же цели через Single полностью пропускают этап обнаружения. Вы сразу обращаетесь к proxy, который уже прошел проверку.
Как команды используют их вместе
Большинство команд, часто обращающихся к одной цели, используют двухэтапный шаблон. Первый вызов является ознакомительным, остальные выполняются напрямую.
Первый вызов направляется в Proxy Finder. Он перебирает пул, проверяет каждого кандидата на соответствие вашим правилам фильтрации и возвращает response вместе с id успешно сработавшего proxy. Этот id становится вашим идентификатором для любых будущих вызовов к той же цели.
Каждый последующий вызов направляется в Single с указанием этого proxy id. Никакого обнаружения, никаких проверок, никаких каскадных повторных попыток. Мы направляем ваш request через указанный proxy и передаем response обратно в виде потока. Именно этот путь обеспечивает задержку в 100 мс на уровне p50.
Если proxy, который работал вчера, сегодня оказывается заблокирован, вы возвращаетесь к Proxy Finder на один вызов для повторного обнаружения, а затем возобновляете запросы через Single с новым id. Мы не пытаемся скрыть неактуальность данных. Если переданный нам proxy id неактивен, мы быстро сообщаем вам об этом, чтобы вы могли выполнить ротацию.
Разделение 99/1 (где Single преобладает по объему, а Proxy Finder используется для обнаружения) объясняет, почему показатели Single выглядят именно так. Дело не в том, что Single сам по себе является более быстрым продуктом. Дело в том, что Single представляет собой стабильный рабочий режим, а Proxy Finder выполняет роль этапа калибровки. Большинство рабочих нагрузок по большей части состоят из стабильного режима.
Если ваша задача формулируется как "получить этот JSON из открытого публичного API, которому неважно, кто обращается", полностью откажитесь от proxy и используйте только Single. Если же ваша задача состоит в том, чтобы "зайти на защищенную страницу из пула одноразовых IP-адресов без риска блокировки", комбинируйте их. Они не заменяют друг друга. Это этапы одного и того же рабочего процесса.
Что мы изменили
Основная часть выигрыша была получена за счет переработки трех компонентов в пути ротации proxy. Ни одна из этих идей не была новой. Это были задачи, которые мы просто откладывали на потом.
Пул перестал доверять недостоверным данным. До обновления каталог proxy хранил записи дольше, чем следовало. Некоторые из этих записей уже были недоступны. Выбор одной из них означал, что вы потратите от 15 до 30 секунд, чтобы выяснить это на практике. Мы перешли к модели, в которой пул отражает реальное состояние активности практически в реальном времени, а picker отдает приоритет IP-адресам, успешная работа которых была зафиксирована недавно.
Оценка качества для каждого proxy, а не просто бинарный статус. Раньше proxy, которому требовалось 5 секунд для ответа, выглядел так же, как и тот, который отвечал за 300 мс, если оба в итоге успешно справлялись с задачей. Теперь picker также отслеживает задержку. Медленные, но работающие proxies сдвигаются в конец очереди. Быстрые используются повторно, пока они активны. Это имеет гораздо большее значение, чем кажется, поскольку длинный хвост распределения задержек в основном состоял из медленных, но рабочих proxies, которые старый picker продолжал выбирать.
Оценка качества по конкретным целям. Proxy, надежно работающий на одном домене, может давать сбои на другом. IP-адреса, которые без проблем работают с одним сайтом, блокируются или попадают под rate limit на другом. Наш picker теперь отслеживает успешность и задержку для каждого целевого хоста, а не только глобально. Когда вы запрашиваете получение данных с определенного домена, мы выбираем из тех proxies, которые недавно показали хорошие результаты именно на этом домене. Глобально эффективные proxies остаются в списке, но proxy с успешной историей работы на конкретной цели имеет приоритет перед тем, который просто хорош в целом.
Более умная эскалация повторных попыток. Раньше при сбое request мы сразу же запускали параллельные попытки. Это было неэффективно, и, что еще хуже, один нерабочий proxy мог вызвать каскад последующих запросов, которые также завершались сбоем. Теперь повторные попытки выполняются последовательно с небольшими паузами между ними, поэтому сбой остается сбоем, а повторная попытка — повторной попыткой, а не множителем нагрузки.
Существует вторая категория изменений, о которой стоит упомянуть, хотя она менее заметна для вас.
Устойчивость к перезапускам. Ранее повторное развертывание любого элемента нашей инфраструктуры обработки requests означало появление окна длительностью от 5 до 15 минут, в течение которого карта оценки качества proxy должна была перестраиваться с нуля. В это время picker, по сути, действовал наугад. Клиенты видели это как всплеск задержки сразу после каждого развертывания. Теперь мы сохраняем эту карту качества между перезапусками. Система запускается в уже прогретом состоянии. На сегодняшний день мы можем развертывать изменения инфраструктуры в середине дня, не вызывая у вас всплесков задержки. Тест перезапуска, проведенный нами сегодня утром, показал 15-секундный сбой соединения и нулевое время восстановления после него. Это незаметное, но важное изменение в нашей периодичности развертывания: нам больше не нужно планировать обновления с оглядкой на ваш трафик.
Более четкие сигналы об ошибках. Если внутри нашей инфраструктуры что-то идет не так, ваша логика повторных попыток теперь получает правильный код состояния HTTP для принятия решений. Временно недоступный backend возвращает 503. Backend, вернувший некорректный JSON, возвращает 502. Фактическая внутренняя ошибка возвращает 500. Раньше все три ситуации выглядели как ошибки 500, из-за чего ваша логика повторных попыток не могла отличить рекомендацию "подождите и попробуйте снова" от критического сбоя. Теперь это возможно.
Что это значит для вас
Если вы запускаете scrapers с ротацией proxies, практическое изменение заключается в том, что ваши показатели p95 и p99 сократились примерно вдвое по сравнению с показателями недельной давности. Среднее время request снижается. Количество повторных попыток из-за медленных, но в итоге срабатывающих proxies уменьшается. Вместе с этим снижается и задержка на хвосте распределения (tail latency), из-за которой задача на 1 000 requests могла занимать час вместо 20 минут.
Если вы используете Single, вы увидите, что оптимизация работы picker приносит пользу в основном на хвосте распределения. p99 снизился до уровня менее 600 мс, а это значит, что даже тот самый неудачный 1% ваших requests теперь возвращается быстро. Single и раньше работал быстро. Теперь он работает стабильно.
Честные ограничения
Мы исправили не все. Несколько моментов, которые по-прежнему актуальны:
Показатель p99 для Proxy Finder все еще составляет около 10 секунд. Мы сократили его вдвое, но длинный хвост распределения никуда не делся. Частично это наша вина (глубина пула, шум picker на редких целях). Во многом это связано с внешними факторами: целевые сайты могут сами по себе работать медленно, применять rate limit к определенным маршрутам, выдавать страницы проверки, анализ которых требует времени, или просто возвращать timeout. Наша инфраструктура может выбрать лучший из доступных IP-адресов, но она не может ускорить целевой сервер, который раздумывает, отвечать ли на запрос. Если ваша задача требует, чтобы каждый request возвращался менее чем за 5 секунд, установите подходящий для вас таймаут на уровне отдельных requests и положитесь на уровень повторных попыток.
Некоторые цели настроены враждебно, и это отражается на ваших показателях. Как упоминалось в начале, показатель success rate в 99,91% не учитывает один хост, который активно блокирует нас на этой неделе. Его включение снижает этот показатель примерно до 95%. И этот хост не уникален. Любой агрегатор, работающий с данными из открытого веба, сталкивается с подобным. Цели меняются от недели к неделе. Обновление picker дает системе гораздо больше шансов обойти враждебные цели, но оно не может повлиять на сайт, который принял решение полностью блокировать трафик. Наша задача состоит в том, чтобы предоставить вам максимально чистые данные в простых случаях и быстро возвращать ошибку в сложных.
Сравнение день к дню содержит погрешности. 24-часовое окно, показанное на графике перцентилей, сравнивает вчерашний день с позавчерашним. Эффекты дня недели, различия в поведении целевых сайтов и состав пула меняются от одного периода к другому. Мы уверены в выбранном направлении (7-дневный график показывает четкую точку перегиба 28 апреля), но если вы хотите протестировать нас на собственной рабочей нагрузке, проводите сравнение как минимум в течение недели.
Что дальше
Переработка picker является фундаментом. Вот несколько задач, которые стоят в очереди за ней:
Общая карта оценки качества между инстансами, чтобы они могли обучаться друг у друга, а не строить независимые карты. Сейчас каждый из них формирует собственное представление о том, какие proxies хороши. Это работает, но неэффективно: каждый инстанс параллельно тратит ресурсы на одно и то же обучение.
Выбор на основе уровня доверия (confidence-based picking), при котором мы отдаем приоритет proxies, реально протестированным за последние несколько минут, а не тем, о состоянии которых мы только догадываемся. Это полезно для клиентов с небольшими объемами трафика, чьи запросы сами по себе не позволяют поддерживать picker в прогретом состоянии.
И в более долгосрочной перспективе: перенос большего количества решений в picker, чтобы оценка качества по конкретной цели стала лишь одним из многих сигналов (таких как профиль задержки цели, шаблоны времени суток, состояние сегментов пула). Теперь у нас есть инфраструктура для реализации этого без замедления быстрого пути (hot path).
Самый дешевый request — это тот, который не пришлось повторять. Обновление picker — это ставка на то, что более точные данные в момент выбора эффективнее, чем увеличение количества попыток постфактум. Первые 24 часа работы подтверждают, что это правильная ставка.