4.2 милиона requests за 24 часа. Среден response: 774 ms. Success rate: 99.91%. Същото натоварване имаше средно 2.5 секунди за седемте дни преди нашето пренаписване. Това е 70% спад в средното време за response, на същия хардуер, срещу същите target сайтове, със същия proxy pool. Пренаписахме частите от request path, които тихомълком костваха вечерите на клиентите.
Това е преглед на промените, как изглеждат реалните числа и защо Single и Proxy Finder се различават с основателна причина.
Първо, една бележка за данните. Числата в тази публикация са от производствения трафик, като е изключен един конкретен target host. Този host активно налагаше rate limit и предизвикателства към requests през цялата седмица, което изкривява всяка метрика, която разглеждате. Ако го включим, успеваемостта пада до около 95%. Но тази разлика от 5% не се дължи на срив в нашата инфраструктура. Това е просто един сайт, който отказва requests, независимо колко добър е нашият picker. Изключихме го, за да можете да видите какво всъщност прави системата при кооперативни targets.
Какво показват данните
Ето среднодневните стойности за нашия производствен трафик през последната седмица:
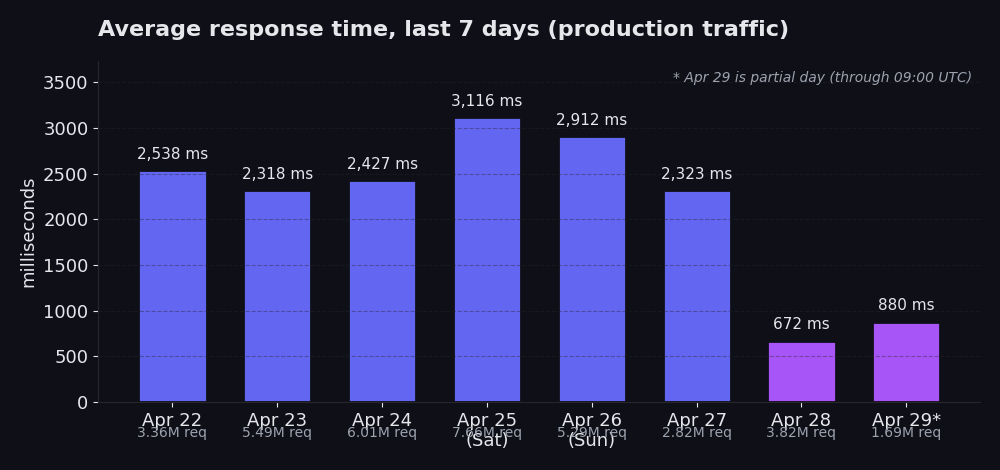
От 22 април до 27 април: средни стойности между 2318 ms и 3116 ms, трафик между 2.8M и 7.7M requests на ден. 25 април се отличава с 3116 ms при 7.7M requests, което е съботният пик (обемът през уикенда е забележимо по-висок и вдига средната стойност). 28 април: 672 ms при 3.8M requests. 29 април (непълен ден, до 09:00 UTC): 880 ms при 1.7M requests до момента.
Същата архитектура. Същите proxies. Същите target сайтове. Различен request path.
Картината с персентилите е по-ясна от средните стойности. Средните стойности могат да скрият лошите опашки. Персентилите не могат.
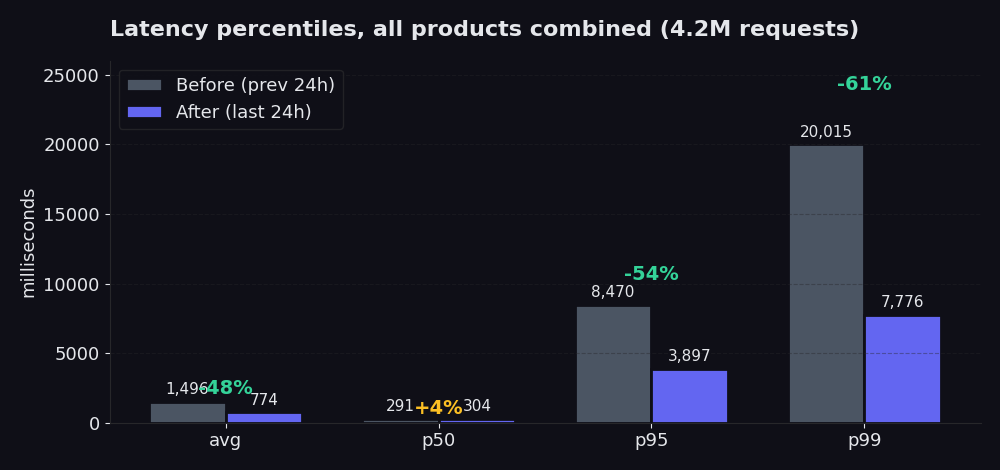
Графиката сравнява 24-те часа след нашето пренаписване с 24-те часа преди него. p50 почти не се промени (и се покачи с 4%, което са честни данни, бързият път и преди си беше наред, а новият picker влага малко повече усилия в началото, за да спести много в опашката). Средната стойност спадна с 48% в този прозорец. p95 спадна от 8.5 секунди до 3.9 секунди, което е 54% съкращение. p99 спадна от 20 секунди до 7.8 секунди, което е 61% съкращение. Точно там е болката и това е, което реално усещате, когато вашият scraper чака най-бавните 5% от requests да се върнат. В сравнение със седемте дни преди пренаписването (където средната стойност се задържаше около 2.5 секунди), днешната средна стойност от 774 ms е 70% спад.
Success rate също се покачи: от 98.85% на 99.91% за същия прозорец. Конкретно при Proxy Finder процентът достигна 99.89%. При Single, 99.96%. Това е числото, с което се гордеем най-много, защото показва колко често връщаме полезни данни още при първия опит, без да се налага retry.
Два продукта, два профила на латентност
Не сравняваме Single и Proxy Finder един с друг. Те решават различни проблеми и имат различни бюджети за латентност. Ако използвате единия, а гледате числата на другия, значи гледате грешното табло с резултати.
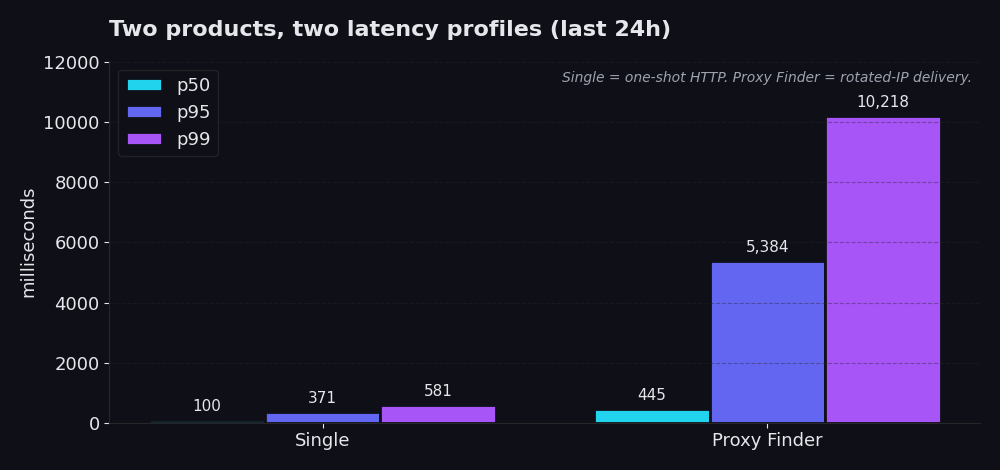
Single е еднократен HTTP request през нашата инфраструктура. Вие ни давате URL и, в приблизително 99% от реалните производствени повиквания, proxy id, за което вече знаете, че работи. Ние извличаме URL адреса през това proxy, а вие получавате response. Без логика за ротация, без каскада от retries, без излишно текучество на proxies. Последните 24 часа: p50 от 100 ms, p95 от 371 ms, p99 от 581 ms. Повечето повиквания приключват за под една пета от секундата. Дори най-лошият 1% се връща за под 600 ms.
Proxy Finder е слоят за откриване. Той ротира вашия request през pool от публични proxies, валидира всеки кандидат, прави retry при неуспех и връща първия response, който действително е проработил, заедно с id на proxy-то, което го е направило. p50 от 445 ms, p95 от 5.4 секунди, p99 от 10.2 секунди. По-бавно е, защото така трябва да бъде. Цялата идея е, че IP адресът, с който вашият scraper достъпва target сайта, е ротиран, временен и за еднократна употреба. Заменяте няколко секунди допълнително време за устойчивост срещу block lists и rate limits.
Причината Single да е толкова бърз не е магия. Тя е, че Single се доверява на нещо, което Proxy Finder вече е трябвало да открие. Когато извикате Proxy Finder веднъж и той върне "this proxy worked, here's its id", следващите извличания към същия target през Single пропускат изцяло стъпката за откриване. Отивате директно към proxy-то, което вече е преминало валидация.
Как екипите ги използват заедно
Повечето екипи, които често достъпват даден target, следват модел от две стъпки. Първото повикване е проучвателно, а останалите са целеви.
Първото повикване отива към Proxy Finder. Той ротира през pool-а, валидира всеки кандидат спрямо вашите правила за приемане и връща response заедно с id на proxy-то, което е проработило. Това id е вашият идентификатор за всяко бъдещо повикване, което иска да достъпи същия target.
Всяко повикване след това отива към Single с прикаченото proxy id. Без откриване, без валидация, без каскада от retries. Ние насочваме вашия request през proxy-то, което сте посочили, и стриймваме обратно получения response. Това е пътят, който достига 100 ms при p50.
Когато proxy-то, което е работило вчера, бъде блокирано днес, вие се връщате към Proxy Finder за едно повикване, за да го откриете отново, след което подновявате извличанията със Single с новото id. Ние не замазваме остарелите данни. Ако подаденото от вас proxy id е неактивно, ви уведомяваме бързо, за да можете да го ротирате.
Разпределението 99/1 (Single доминира по обем, Proxy Finder доминира при откриването) е причината нашите числа за Single да изглеждат по този начин. Не че Single е по природа по-бърз продукт. Просто Single е установеното състояние, а Proxy Finder е стъпката за калибриране. Повечето работни натоварвания са предимно в установено състояние.
Ако задачата ви е "извлечи този JSON от чист публичен API, който не се интересува кой го вика", пропуснете proxy-то изцяло и използвайте само Single. Ако задачата ви е "достъпи тази защитена страница от pool с временни IP адреси, без да бъдеш маркиран", ги комбинирайте. Те не са алтернативи. Те са етапи от един и същ работен процес.
Какво променихме
По-голямата част от успеха дойде от пренаписването на три неща в пътя за ротация на proxies. Нито едно от тях не беше нова идея. Просто бяха неща, които бяхме отлагали.
Pool-ът спря да се доверява на лоши данни. Преди пренаписването директорията с proxies пазеше записи по-дълго, отколкото трябваше. Някои от тези записи вече не бяха достъпни. Избирането на някой от тях означаваше да прекарате 15 до 30 секунди, за да го разберете по трудния начин. Преминахме към модел, при който pool-ът отразява това, което действително е активно в почти реално време, а picker-ът предпочита IP адреси, за които наскоро сме видели, че работят успешно.
Quality scores за всяко proxy, а не просто работещо/неработещо. Преди proxy, на което му отнемаше 5 секунди да върне response, изглеждаше по същия начин като такова, на което му отнемаше 300 ms, стига и двете в крайна сметка да успеят. Сега picker-ът следи и латентността. Бавните, но работещи proxies се изтласкват назад в опашката. Бързите се използват повторно, докато са активни. Това е по-важно, отколкото звучи, тъй като дългата опашка на разпределението на латентността се състои предимно от бавни, но работещи proxies, които старият picker продължаваше да избира.
Quality scores за всеки target. Дадено proxy, което е надеждно за един домейн, може да е нестабилно за друг. IP адресите, които работят безпроблемно срещу един сайт, биват блокирани или подложени на rate limit в друг. Нашият picker вече следи успеваемостта и латентността за всеки target host, а не само глобално. Когато поискате извличане от конкретен домейн, ние избираме от тези proxies, които действително са се представили добре на този домейн наскоро. Глобално добрите proxies остават в играта, но proxy със силна история на конкретния target има предимство пред такова със силна история като цяло.
По-умна ескалация на retries. Когато даден request се провалеше, преди веднага стартирахме паралелни опити. Това беше неефективно и, което е по-лошо, едно лошо proxy можеше да задейства каскада от последващи опити, които също се проваляха един след друг. Сега retries ескалират последователно с кратки изчаквания (backoffs) между опитите, така че провалът си е провал, а retry си е retry, а не мултипликатор.
Има и втора категория промени, които си струва да се споменат, въпреки че са по-малко видими за вас.
Restart resilience. Преди повторното внедряване (redeploy) на която и да е част от нашата request инфраструктура означаваше прозорец от 5 до 15 минути, в който картата с оценки за качество на proxies трябваше да се изгради наново от нулата. По време на този прозорец picker-ът на практика гадаеше. Клиентите виждаха това като пик в латентността веднага след всеки deploy. Сега запазваме тази карта с оценки при рестартирания. Системата стартира готова (warm). Към днешна дата можем да внедряваме промени в инфраструктурата по средата на деня, без това да води до пик в латентността за вас. Тестът с рестартиране, който проведохме тази сутрин, показа 15-секундно прекъсване на връзката и нулева нужда от време за възстановяване след това. Това е тиха, но значима промяна в нашия ритъм на внедряване: вече не се налага да планираме redeploys съобразно вашия трафик.
По-чисти failure signals. Когато нещо в нашата инфраструктура се обърка, вашата retry логика вече получава правилния HTTP статус код, въз основа на който да действа. Backend, който временно е недостъпен, връща 503. Backend, който е върнал невалиден JSON, връща 502. Истинска вътрешна грешка връща 500. Преди и трите изглеждаха като 500, което означаваше, че вашата retry логика не можеше да разграничи "изчакай и опитай отново" от "това е счупено, ескалирай". Сега вече може.
Как изглежда това за вас
Ако използвате scrapers с ротирани proxies, практическата промяна е, че вашите p95 и p99 са съкратени приблизително наполовина в сравнение с преди една седмица. Средното време за request намалява. Намаляват и retries, дължащи се на бавни, но в крайна сметка работещи proxies. Латентността на опашката (tail latency), която кара една задача с 1000 requests да отнеме час вместо 20 минути, спада заедно с това.
Ако използвате Single, ще видите, че работата по picker-а се отплаща най-вече в опашката. p99 спадна до под 600 ms, което означава, че дори вашият каръшки 1% от requests сега се връща бързо. Single и преди си беше бърз. Сега вече е и консистентен.
Честни ограничения
Не сме поправили всичко. Няколко специфични неща, които все още са в сила:
p99 на Proxy Finder все още е около 10 секунди. Намалихме го наполовина, но дългата опашка е реалност. Част от това се дължи на нас (дълбочина на pool-а, шум в picker-а при редки targets). Голяма част обаче не е: самите target сайтове могат да бъдат бавни, могат да налагат rate limit на специфични маршрути, могат да показват страници с предизвикателства, чиято проверка отнема време, или просто да изтече времето за изчакване (timeout). Нашата инфраструктура може да избере най-добрия наличен IP адрес, но не може да ускори target сървър, който тепърва решава дали да отговори. Ако работата ви зависи от това всеки request да се връща за под 5 секунди, задайте timeout за всеки request, който съответства на вашия толеранс, и се доверете на слоя за retry.
Някои targets са враждебни и това се вижда в числата ви. Както споменахме в началото, успеваемостта от 99.91% изключва един host, който активно ни предизвикваше тази седмица. Включването му сваля процента до около 95%. Този host не е изключение. Всеки агрегатор, работещ с данни от публичната мрежа, се сблъсква с това. Target-ът се променя всяка седмица. Пренаписването на picker-а дава на системата много по-добър шанс да заобикаля враждебните targets, но не може да надделее над сайт, който е решил категорично да откаже трафика. Нашата задача е да ви предоставим възможно най-чистите данни при кооперативните случаи и да се проваляме бързо (fail fast) при враждебните.
Сравнението в рамките на същия ден съдържа шум. 24-часовият прозорец, който показваме в графиката с персентилите, сравнява вчерашния ден с предходния. Ефектите от деня от седмицата, отклоненията в target сайтовете и съставът на pool-а се променят между всеки два прозореца. Уверени сме в посоката (7-дневната графика показва ясна повратна точка на 28 април), но ако ни тествате спрямо собственото си натоварване, направете сравнението за период от поне една седмица.
Какво следва
Пренаписването на picker-а е основата. Няколко неща, които сме подготвили след него:
Споделена карта с оценки за качество (quality-score map) между инстанциите, така че те да се учат една от друга, вместо да изграждат независими карти. В момента всяка от тях има собствена представа за това кои proxies са добри. Това работи, но е неефективно: всяка инстанция плаща една и съща цена за учене паралелно.
Избор, базиран на увереност (confidence-based picking), при който предпочитаме proxies, които действително сме тествали през последните няколко минути, пред такива, за които само гадаем. Полезно за клиенти с малък обем на трафика, чийто трафик сам по себе си не поддържа picker-а готов (warm).
И в по-дългосрочен план: прехвърляне на повече решения към picker-а, така че оценката за качество за всеки target да стане просто един сигнал сред много други (профил на латентност на target-а, модели според времето от денонощието, състояние на сегментите в pool-а). Сега вече съществува инфраструктурата това да се прави, без да се забавя бързият път (hot path).
Най-евтиният request е този, за който не е трябвало да правим retry. Пренаписването на picker-а е залогът, че по-добрите данни в момента на избор превъзхождат повечето опити след събитието. Данните от първите 24 часа показват, че това е правилният залог.