24 小时内处理 4.2M 次 request。平均 response 时间:774 ms。成功率:99.91%。在重建之前的七天里,同样的工作负载平均耗时 2.5 秒。这意味着在相同的硬件、相同的目标网站以及相同的 proxy pool 下,平均响应时间下降了 70%。我们重建了 request 路径中那些悄悄消耗客户下班时间的环节。
本文记录了具体的变化、数据的实际表现,以及 Single 和 Proxy Finder 存在差异的合理原因。
首先对数据做一个说明。本文中的数据来自生产流量,排除了一个特定的目标主机。该主机整周都在积极地进行 rate limit 并对 request 发起挑战,这会扭曲你看到的每一个指标。如果将其包含在内,成功率会降至约 95%。但那 5% 的差距并不是我们的基础设施出了问题。这是因为无论我们的 picker 有多好,该网站都会拒绝 request。我们将其排除在外,以便你能看到系统在配合的目标上实际表现如何。
数据说明了什么
以下是过去一周我们生产流量的每日平均值:
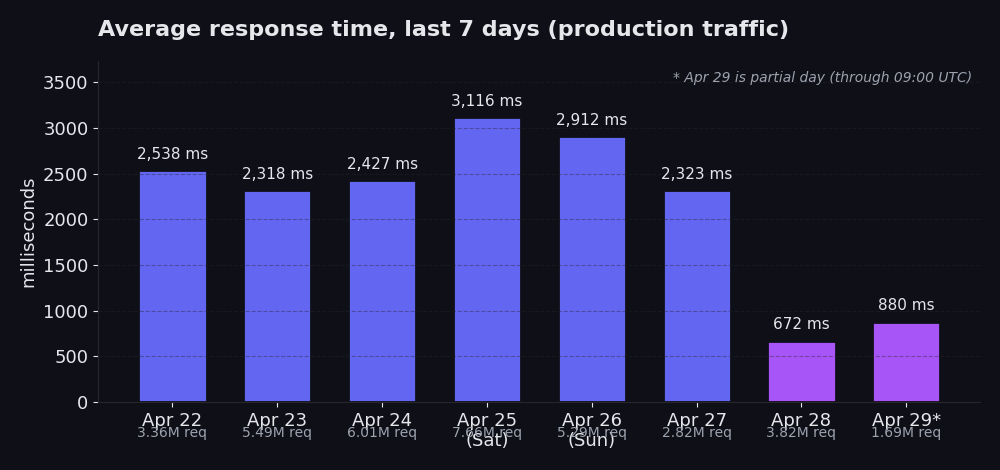
4 月 22 日至 4 月 27 日:平均值在 2,318 ms 至 3,116 ms 之间,每日流量在 2.8M 至 7.7M 次 request 之间。4 月 25 日表现突出,在 7.7M 次 request 中达到 3,116 ms,这是周六的峰值(周末流量明显更高,推高了平均值)。4 月 28 日:3.8M 次 request 中平均为 672 ms。4 月 29 日(部分时间,截至 UTC 09:00):目前 1.7M 次 request 中平均为 880 ms。
相同的架构。相同的 proxy。相同的目标网站。不同的 request 路径。
百分位数图表比平均值更清晰。平均值会掩盖糟糕的尾部数据。百分位数则不会。
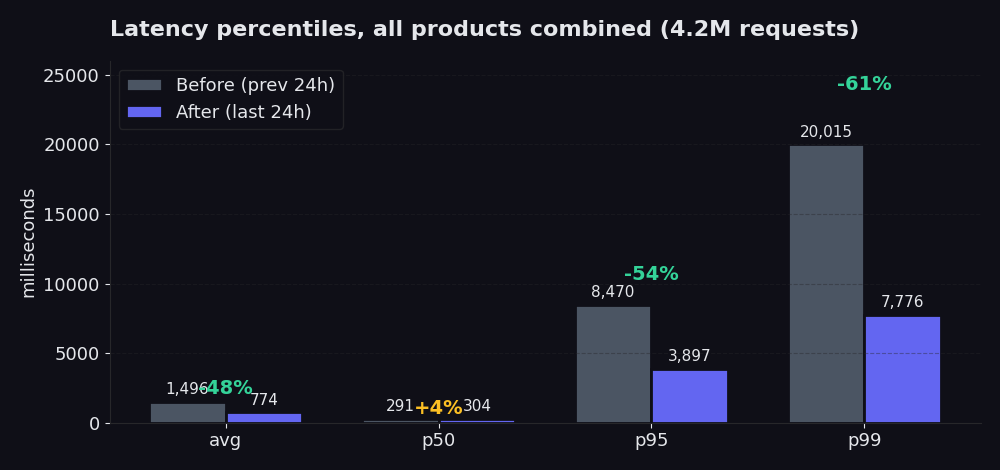
该图表对比了重建后 24 小时与重建前 24 小时的数据。p50 几乎没有变化(微升了 4%,这是真实的数据;快速路径本来就表现良好,而新的 picker 在前期多花了一点精力,从而在尾部节省了大量时间)。在此时间窗口内,平均值下降了 48%。p95 从 8.5 秒降至 3.9 秒,降幅达 54%。p99 从 20 秒降至 7.8 秒,降幅达 61%。这就是痛点所在,也是当你的 scraper 等待最慢的 5% 的 request 返回时你实际感受到的延迟。与重建前的七天(平均值保持在 2.5 秒左右)相比,今天 774 ms 的平均值下降了 70%。
成功率也有所上升:在同一窗口期内从 98.85% 升至 99.91%。特别是在 Proxy Finder 上,成功率达到了 99.89%。在 Single 上,成功率为 99.96%。这是我们最自豪的数据,因为它告诉你在第一次尝试时,我们在无需重试的情况下返回有用数据的频率。
两种产品,两种延迟特征
我们不会将 Single 和 Proxy Finder 进行对比。它们解决不同的问题,并且拥有不同的延迟预算。如果你在使用其中一个,却看着另一个的数据,那你就看错记分牌了。
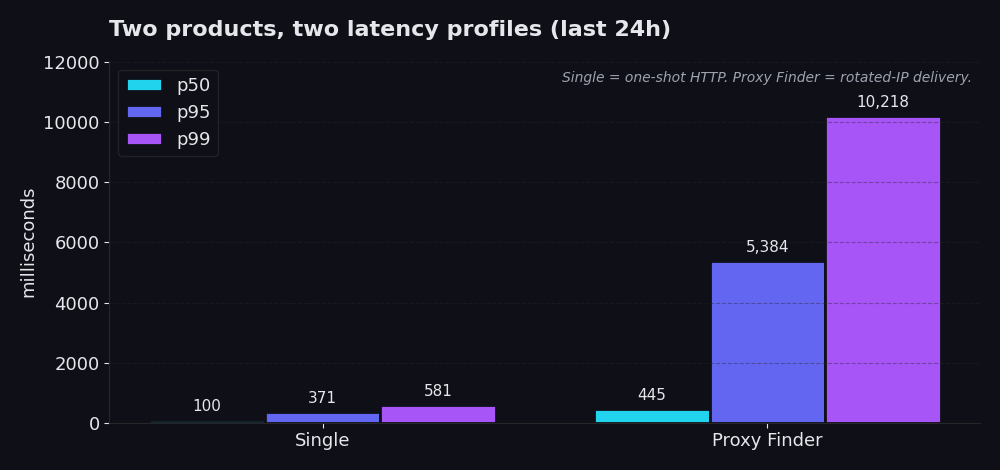
Single 是通过我们基础设施进行的一次性 HTTP request。你给我们一个 URL,并且在约 99% 的实际生产调用中,提供一个你已知有效的 proxy id。我们通过该 proxy 获取 URL,你获取 response。没有轮换逻辑,没有级联重试,没有 proxy 频繁更替。过去 24 小时:p50 为 100 ms,p95 为 371 ms,p99 为 581 ms。大多数调用在不到五分之一秒内完成。即使是最糟糕的 1% 也能在 600 ms 内返回。
Proxy Finder 是发现层。它在公共 proxy pool 中轮换你的 request,验证每个候选 proxy,在失败时进行重试,并返回第一个实际有效的 response,以及执行该操作的 proxy id。p50 为 445 ms,p95 为 5.4 秒,p99 为 10.2 秒。慢是必然的。其核心在于,你的 scraper 访问目标网站时所使用的 IP 是轮换的、即用即弃的。你用几秒钟的开销换取了对 block list 和 rate limit 的防御能力。
Single 如此之快并非魔法。而是因为 Single 信任了 Proxy Finder 必须去发现的信息。当你调用一次 Proxy Finder 并且它返回 “此 proxy 有效,这是它的 id” 时,后续通过 Single 对相同目标的获取将跳过整个发现步骤。你直接访问已经通过验证的 proxy。
团队如何协同使用它们
大多数频繁访问目标的团队都遵循两步模式。第一次调用是探索性的;其余的则是确定的。
第一次调用发送给 Proxy Finder。它在 pool 中进行轮换,根据你的接受规则验证每个候选 proxy,并返回 response 以及有效的 proxy id。该 id 就是你未来任何想要访问相同目标的调用的句柄。
此后的每一次调用都会发送给 Single,并附带该 proxy id。没有发现,没有验证,没有级联重试。我们通过你指定的 proxy 路由你的 request,并将 response 流式传输回来。这就是在 p50 达到 100 ms 的路径。
当昨天有效的 proxy 今天被 block 时,你可以回退到 Proxy Finder 进行一次调用以重新发现,然后使用新的 id 继续进行 Single 获取。我们不会粉饰过期数据。如果你交给我们的 proxy id 已失效,我们会快速告知你,以便你进行轮换。
99/1 的比例(Single 占据了大部分流量, Proxy Finder 主要用于发现)就是我们的 Single 数据如此亮眼的原因。这并不是因为 Single 本质上是一个更快的产品。而是因为 Single 代表了稳定状态,而 Proxy Finder 是校准步骤。大多数工作负载大部分时间都处于稳定状态。
如果你的任务是“从一个不在乎谁在调用的干净公开 API 中获取此 JSON”,请完全跳过 proxy,直接单独使用 Single。如果你的任务是“从一次性 IP pool 中访问此受保护的页面而不被标记”,请将它们结合使用。它们不是替代方案。它们是同一个工作流的不同阶段。
我们做出了哪些改变
大部分提升来自于重建 proxy 轮换路径中的三样东西。它们都不是新想法。只是我们一直在推迟实施的事情。
pool 停止信任糟糕的数据。 在重建之前,proxy 目录保留条目的时间超出了应有的期限。其中一些条目已经无法访问。选择其中一个意味着你要花 15 到 30 秒的时间才能艰难地发现这一点。我们转向了一种新模型,使 pool 能够近乎实时地反映实际存活的 proxy,并且 picker 会更倾向于选择我们最近看到成功过的 IP。
针对每个 proxy 的质量评分,而不仅仅是可用与否。 以前,只要两者最终都成功,一个耗时 5 秒响应的 proxy 看起来与一个耗时 300 ms 的 proxy 没有区别。现在 picker 也会追踪延迟。运行缓慢但可用的 proxy 会被推到队列后方。快速的 proxy 会在保持活跃时被重复使用。这比听起来更重要,因为延迟分布的长尾基本上都是旧 picker 经常选择的运行缓慢但可用的 proxy。
针对每个目标的质量评分。 在一个域名上可靠的 proxy 在另一个域名上可能会不稳定。在某个网站上运行良好的 IP 在另一个网站上可能会被 block 或 rate limit。我们的 picker 现在会针对每个目标主机追踪成功率和延迟,而不仅仅是全局追踪。当你请求针对特定域名进行获取时,我们会从最近在该域名上实际表现良好的 proxy 中进行选择。全局表现良好的 proxy 仍会参与竞争,但在特定目标上拥有良好记录的 proxy 的优先级会高于整体记录良好的 proxy。
更智能的重试升级。 当一个 request 失败时,我们过去会立即展开并行尝试。这很浪费,更糟糕的是,单个糟糕的 proxy 可能会触发一系列接连失败的后续尝试。现在,重试会按顺序升级,并在尝试之间进行短暂的 backoff,因此失败就是失败,重试就是重试,而不是乘数效应。
还有第二类值得提及的变化,尽管它们对你来说不那么显而易见。
重启韧性。 以前,重新部署我们的任何 request 基础设施都意味着有 5 到 15 分钟的时间窗口,在此期间 proxy 质量评分图必须从头开始重建。在这个窗口期内,picker 基本上是在盲猜。客户会看到每次部署后立即出现延迟尖峰。我们现在跨重启持久化该质量图。系统启动即处于热状态。截至今天,我们可以在中午部署基础设施更改,而不会给你带来延迟尖峰。我们今天早上运行的重启测试显示,连接仅出现了 15 秒的短暂波动,之后恢复时间为零。这是我们部署节奏中一个悄然但意义重大的变化:我们不再需要根据你的流量来安排重新部署。
更清晰的失败信号。 当我们基础设施内部出现问题时,你的重试逻辑现在会获得正确的 HTTP 状态码以采取行动。暂时不可用的后端返回 503。返回异常 JSON 的后端返回 502。真正的内部错误返回 500。以前,这三者看起来都像 500,这意味着你的重试逻辑无法区分“等待并重试”与“此服务已损坏,需升级处理”。现在它可以了。
这对你意味着什么
如果你在针对轮换 proxy 运行 scraper,实际的变化是你的 p95 and p99 均比一周前减少了大约一半。平均 request 时间下降了。由于 proxy 缓慢但最终可用而导致的重试减少了。尾部延迟(正是它导致一个包含 1,000 次 request 的任务需要一个小时而不是 20 分钟)也随之下降。
如果你在运行 Single,你会看到 picker 的优化工作主要在尾部数据上发挥作用。p99 降至 600 ms 以下,这意味着即使是你那不幸的 1% 的 request 现在也能快速返回。Single 本来就很快。现在它更稳定了。
坦诚的局限性
我们并没有解决所有问题。以下是一些仍然适用的具体情况:
Proxy Finder 的 p99 仍保持在 10 秒左右。 我们将其缩短了一半,但长尾效应是真实存在的。这其中有一些是我们的原因(pool 深度、罕见目标上的 picker 噪点)。很大一部分原因则不在于我们:目标网站自身可能很慢、可能会对特定路由进行 rate limit、可能会提供需要时间检查的验证页面,或者可能直接 timeout。我们的基础设施可以挑选最佳的可用 IP,但它无法加速一个正在决定是否做出响应的目标服务器。如果你的任务依赖于每次 request 都在 5 秒内返回,请设置一个符合你容忍度的单次 request timeout,并信任重试层。
某些目标是敌对的,这会体现在你的数据中。 正如开头所提到的,99.91% 的成功率排除了一个本周正积极对我们发起挑战的主机。如果将其包含在内,成功率会降至约 95%。该主机并非特例。任何处理公共网络数据的聚合器都会遇到这种情况。目标每周都在变化。picker 的重建使系统在绕过敌对目标方面有了更好的机会,但它无法推翻一个已决定完全拒绝流量的网站。我们的工作是在配合的情况下为你提供尽可能干净的数据,并在面对敌对目标时快速失败。
同日对比存在噪点。 我们在百分位数图表中展示的 24 小时窗口对比了昨天和前天。星期几效应、目标网站差异以及 pool 的构成在任何两个窗口期之间都会发生变化。我们对这一趋势充满信心(7 天图表显示 4 月 28 日有一个清晰的拐点),但如果你针对自己的工作负载对我们进行基准测试,请至少运行一周的对比。
下一步计划
picker 的重写是基础。我们在此之后还排队准备了以下几件事:
跨实例共享质量评分图,以便它们相互学习,而不是构建独立的图。目前,它们各自记录着哪些 proxy 表现良好的画像。这虽然可行,但很浪费:每个实例都在并行支付相同的学习成本。
基于置信度的选择,即我们更倾向于选择我们在过去几分钟内实际测试过的 proxy,而不是我们猜测的 proxy。这对于低流量客户非常有用,因为他们的流量本身不足以让 picker 保持活跃状态。
从更长远来看:将更多决策推入 picker,使每个目标的质量评分成为众多信号之一(目标延迟特征、时间段模式、pool 分段健康状况)。现在已经具备了实现这一目标的基础设施,且不会减慢热路径。
最省钱的 request 是我们不需要重试的 request。picker 的重建是一次赌注,即在选择瞬间拥有更好的数据胜过事后进行更多尝试。前 24 小时的证据表明,这是一个正确的赌注。