4,2 triệu request trong 24 giờ. Response trung bình: 774 ms. Tỷ lệ thành công: 99,91%. Cùng một khối lượng công việc đó đã mất trung bình 2,5 giây trong bảy ngày trước khi chúng tôi rebuild. Đó là mức giảm 70% thời gian response trung bình, trên cùng một phần cứng, đối với cùng các trang web mục tiêu, với cùng một proxy pool. Chúng tôi đã xây dựng lại các phần của request path vốn đang âm thầm làm lãng phí thời gian buổi tối của khách hàng.
Đây là bài viết chi tiết về những gì đã thay đổi, các con số thực tế trông như thế nào, và lý do tại sao Single và Proxy Finder lại có sự khác biệt.
Trước tiên là một lưu ý về dữ liệu. Các con số trong bài viết này được lấy từ production traffic, ngoại trừ một host mục tiêu cụ thể. Host đó đã liên tục rate-limiting và challenge các request trong suốt cả tuần, làm sai lệch mọi chỉ số mà bạn quan sát. Nếu tính cả host đó, tỷ lệ thành công sẽ giảm xuống còn khoảng 95%. Nhưng khoảng cách 5% đó không phải do hạ tầng của chúng tôi bị lỗi. Đó là do một trang web từ chối các request, bất kể picker của chúng tôi tốt đến mức nào. Chúng tôi đã loại bỏ nó để bạn có thể thấy hệ thống thực sự hoạt động như thế nào trên các mục tiêu hợp tác.
Những gì dữ liệu hiển thị
Dưới đây là mức trung bình hàng ngày trên toàn bộ production traffic của chúng tôi trong tuần qua:
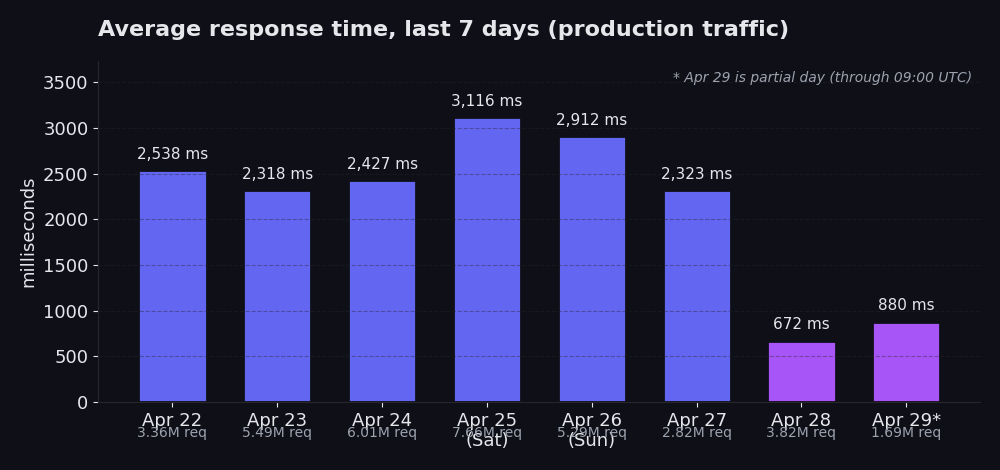
Từ ngày 22 tháng 4 đến ngày 27 tháng 4: trung bình từ 2.318 ms đến 3.116 ms, traffic từ 2,8M đến 7,7M request mỗi ngày. Ngày 25 tháng 4 nổi bật với mức 3.116 ms trên 7,7M request, đây là mức đỉnh điểm của ngày Thứ Bảy (weekend volume thường cao hơn rõ rệt và đẩy mức trung bình lên). Ngày 28 tháng 4: 672 ms trên 3,8M request. Ngày 29 tháng 4 (chưa trọn ngày, tính đến 09:00 UTC): hiện tại là 880 ms trên 1,7M request.
Cùng một kiến trúc. Cùng các proxy. Cùng các trang web mục tiêu. Khác biệt ở request path.
Bức tranh percentile rõ ràng hơn so với mức trung bình. Mức trung bình có thể che giấu các bad tail tồi tệ. Percentile thì không.
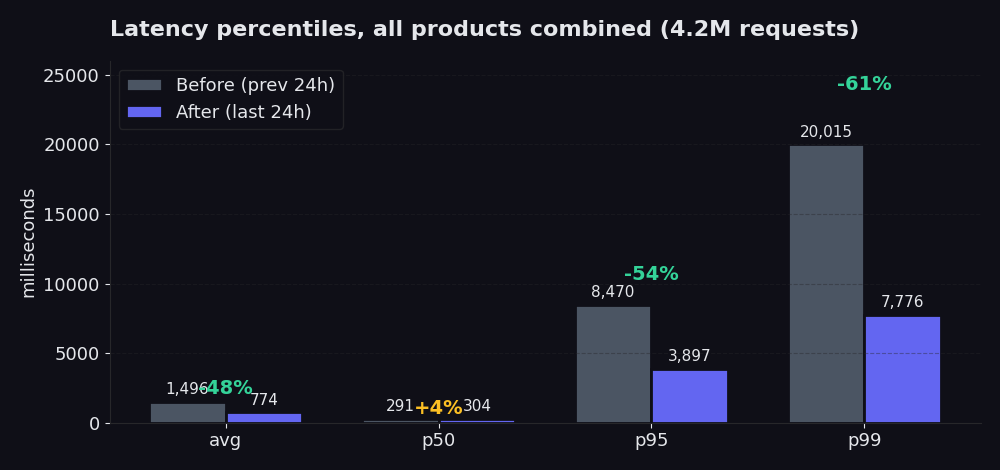
Biểu đồ so sánh 24 giờ sau khi rebuild với 24 giờ trước đó. p50 hầu như không thay đổi (và tăng nhẹ 4%, đây là dữ liệu trung thực; fast path vốn đã hoạt động tốt và picker mới tốn thêm một chút tài nguyên ban đầu để tiết kiệm rất nhiều ở phần tail). Mức trung bình giảm 48% trong khoảng thời gian đó. p95 giảm từ 8,5 giây xuống còn 3,9 giây, giảm 54%. p99 giảm từ 20 giây xuống còn 7,8 giây, giảm 61%. Đó chính là nơi điểm nghẽn tồn tại, và là những gì bạn thực sự cảm nhận được khi scraper của bạn đang phải chờ đợi 5% request chậm nhất phản hồi. So với bảy ngày trước khi rebuild (nơi mức trung bình duy trì khoảng 2,5 giây), mức trung bình 774 ms của ngày hôm nay là một mức giảm 70%.
Tỷ lệ thành công cũng tăng lên: từ 98,85% lên 99,91% trong cùng một khoảng thời gian. Riêng trên Proxy Finder, tỷ lệ này đạt 99,89%. Trên Single, 99,96%. Đó là con số chúng tôi tự hào nhất, vì nó cho bạn biết tần suất chúng tôi trả về dữ liệu hữu ích ngay trong lần thử đầu tiên mà không cần phải retry.
Hai sản phẩm, hai latency profile
Chúng tôi không so sánh Single và Proxy Finder với nhau. Chúng giải quyết các vấn đề khác nhau và có latency budget khác nhau. Nếu bạn đang sử dụng sản phẩm này nhưng lại nhìn vào con số của sản phẩm kia, bạn đang xem nhầm bảng điểm.
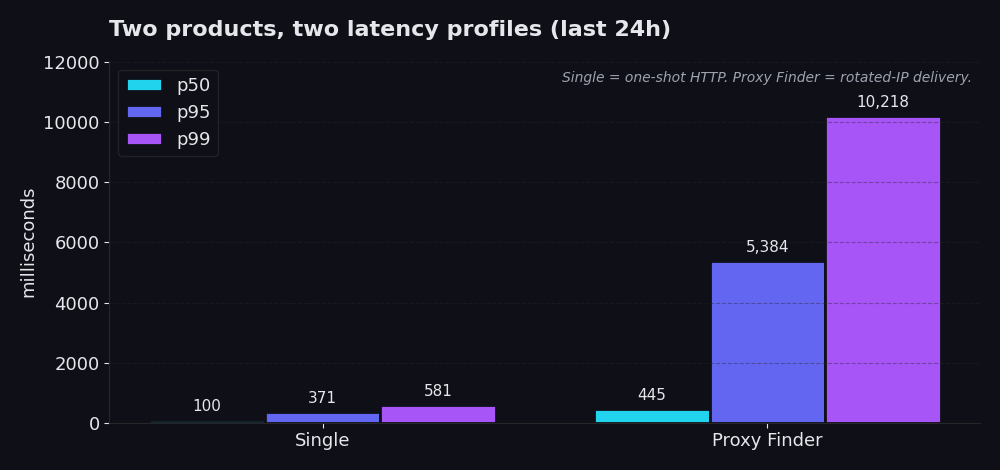
Single là một one-shot HTTP request thông qua hạ tầng của chúng tôi. Bạn cung cấp cho chúng tôi một URL và, trong khoảng 99% các cuộc gọi production thực tế, một proxy id mà bạn đã biết là hoạt động tốt. Chúng tôi fetch URL đó thông qua proxy đó, bạn nhận được response. Không có rotation logic, không có retry cascade, không có proxy churn. 24 giờ qua: p50 là 100 ms, p95 là 371 ms, p99 là 581 ms. Hầu hết các cuộc gọi hoàn thành trong chưa đầy một phần năm giây. Ngay cả 1% tệ nhất cũng phản hồi trong chưa đầy 600 ms.
Proxy Finder là discovery layer. Nó rotate request của bạn qua một pool các public proxy, validate từng ứng viên, retry khi thất bại, và trả về response đầu tiên thực sự hoạt động, cùng với id của proxy đã thực hiện việc đó. p50 là 445 ms, p95 là 5,4 giây, p99 là 10,2 giây. Chậm hơn vì nó bắt buộc phải như vậy. Toàn bộ mục đích là để IP mà scraper của bạn dùng để truy cập trang web mục tiêu được rotate, tạm thời và có thể loại bỏ. Bạn đang đánh đổi vài giây overhead để lấy khả năng chống lại các block list và rate limit.
Lý do Single nhanh như vậy không phải là phép thuật. Đó là vì Single tin tưởng vào những gì Proxy Finder đã phải khám phá trước đó. Khi bạn gọi Proxy Finder một lần và nó trả về "proxy này hoạt động tốt, đây là id của nó," các lượt fetch tiếp theo tới cùng một mục tiêu thông qua Single sẽ bỏ qua toàn bộ bước khám phá. Bạn đi thẳng tới proxy đã vượt qua bước validation.
Cách các đội ngũ kết hợp chúng với nhau
Hầu hết các đội ngũ truy cập một mục tiêu thường xuyên đều tuân theo mô hình hai bước. Cuộc gọi đầu tiên mang tính khám phá, các cuộc gọi còn lại là cam kết.
Cuộc gọi đầu tiên được gửi tới Proxy Finder. Nó rotate qua pool, validate từng ứng viên dựa trên các accept rules của bạn, và trả về response cùng với id của proxy hoạt động tốt. ID đó là handle của bạn cho bất kỳ cuộc gọi nào trong tương lai muốn truy cập vào cùng mục tiêu đó.
Mọi cuộc gọi sau đó đều được gửi tới Single, kèm theo proxy id. Không có discovery, không có validation, không có retry cascade. Chúng tôi định tuyến request của bạn qua proxy bạn đã chỉ định và stream response trở lại. Đó là con đường đạt mức 100 ms ở p50.
Khi proxy hoạt động ngày hôm qua bị chặn vào ngày hôm nay, bạn sẽ quay lại sử dụng Proxy Finder cho một cuộc gọi để khám phá lại, sau đó tiếp tục các lượt fetch bằng Single với id mới. Chúng tôi không che giấu sự lỗi thời. Nếu một proxy id bạn gửi cho chúng tôi đã chết, chúng tôi sẽ thông báo cho bạn nhanh chóng để bạn có thể rotate.
Sự phân chia 99/1 (Single chiếm ưu thế về volume, Proxy Finder chiếm ưu thế về discovery) là lý do tại sao các con số của Single lại trông như vậy. Không phải vì Single bản chất là một sản phẩm nhanh hơn. Mà là vì Single đại diện cho steady state và Proxy Finder là bước calibration. Hầu hết các workload phần lớn đều ở steady state.
Nếu công việc của bạn là "fetch JSON này từ một clean public API không quan tâm ai đang gọi," hãy bỏ qua proxy hoàn toàn và sử dụng Single độc lập. Nếu công việc của bạn là "truy cập trang web được bảo vệ này từ một pool các IP tạm thời mà không bị gắn cờ," hãy kết hợp chúng. Chúng không phải là các giải pháp thay thế lẫn nhau. Chúng là các giai đoạn của cùng một workflow.
Những gì chúng tôi đã thay đổi
Phần lớn chiến thắng đến từ việc rebuild ba thứ trong proxy rotation path. Không có điều nào trong số đó là ý tưởng mới. Chúng chỉ là những việc chúng tôi đã trì hoãn trước đây.
Pool đã ngừng tin tưởng vào dữ liệu xấu. Trước khi rebuild, proxy directory đã giữ lại các bản ghi lâu hơn mức cần thiết. Một số bản ghi trong số đó không còn khả năng kết nối nữa. Việc chọn một trong số chúng đồng nghĩa với việc bạn phải mất từ 15 đến 30 giây để nhận ra bài học xương máu. Chúng tôi đã chuyển sang một mô hình nơi pool phản ánh những gì thực sự hoạt động trong thời gian gần như thực tế (near real-time), và picker sẽ ưu tiên các IP mà chúng tôi ghi nhận là đã thành công gần đây.
Quality score cho từng proxy, không chỉ đơn thuần là hoạt động hay không. Trước đây, một proxy mất 5 giây để phản hồi cũng trông giống như một proxy chỉ mất 300 ms, miễn là cả hai cuối cùng đều thành công. Giờ đây, picker cũng theo dõi cả latency. Các proxy chậm-nhưng-hoạt-động sẽ bị đẩy xuống cuối hàng đợi. Những proxy nhanh sẽ được tái sử dụng khi chúng còn hoạt động tốt (hot). Điều này quan trọng hơn những gì bạn nghĩ, bởi vì long tail của phân phối latency hầu hết là các proxy chậm-nhưng-hoạt-động mà picker cũ liên tục lựa chọn.
Quality score theo từng mục tiêu (per-target quality score). Một proxy đáng tin cậy trên một tên miền này có thể hoạt động chập chờn trên một tên miền khác. Các IP hoạt động trơn tru trên một trang web có thể bị chặn hoặc rate-limited trên một trang web khác. Picker của chúng tôi hiện theo dõi tỷ lệ thành công và latency trên từng host mục tiêu, chứ không chỉ trên toàn cầu. Khi bạn yêu cầu fetch đối với một tên miền cụ thể, chúng tôi sẽ chọn từ các proxy thực sự hoạt động tốt trên tên miền đó gần đây. Các proxy tốt trên toàn cầu vẫn được giữ lại, nhưng một proxy có lịch sử hoạt động tốt trên chính mục tiêu cụ thể đó sẽ được ưu tiên hơn một proxy chỉ có lịch sử tốt trên tổng thể.
Smarter retry escalation. Trước đây, khi một request thất bại, chúng tôi thường ngay lập tức fan out song song. Điều đó gây lãng phí, và tệ hơn, một proxy xấu duy nhất có thể kích hoạt một chuỗi các lượt thử tiếp theo và tất cả đều lần lượt thất bại. Giờ đây, các lượt retry sẽ leo thang tuần tự với các khoảng backoff ngắn giữa các lần thử, nhờ đó một thất bại chỉ là một thất bại và một retry chỉ là một retry, chứ không phải là một cấp số nhân.
Có một nhóm thay đổi thứ hai đáng được nhắc đến, mặc dù nó ít hiển thị trực tiếp với bạn hơn.
Restart resilience. Trước đây, việc redeploy bất kỳ hạ tầng request nào của chúng tôi đồng nghĩa với việc có một khoảng thời gian từ 5 đến 15 phút mà proxy quality-score map phải tự xây dựng lại từ đầu. Trong khoảng thời gian đó, picker về cơ bản là đang đoán mò. Khách hàng sẽ thấy điều đó dưới dạng một latency spike ngay sau mỗi lần deploy. Giờ đây, chúng tôi persist bản đồ chất lượng đó qua các lần khởi động lại. Hệ thống sẽ khởi động ở trạng thái warm. Kể từ hôm nay, chúng tôi có thể deploy các thay đổi hạ tầng vào giữa ngày mà không gây ra tình trạng latency spike cho bạn. Thử nghiệm khởi động lại mà chúng tôi thực hiện sáng nay cho thấy một sự cố kết nối nhỏ (blip) kéo dài 15 giây và không mất thời gian phục hồi sau đó. Đó là một thay đổi thầm lặng nhưng đầy ý nghĩa trong nhịp độ deploy của chúng tôi: chúng tôi không còn phải lên lịch redeploy xoay quanh traffic của bạn nữa.
Cleaner failure signals. Khi có sự cố xảy ra bên trong hạ tầng của chúng tôi, logic retry của bạn giờ đây sẽ nhận được đúng HTTP status code để xử lý. Một backend tạm thời không khả dụng sẽ trả về mã 503. Một backend trả về malformed JSON sẽ trả về mã 502. Một lỗi nội bộ thực sự sẽ trả về mã 500. Trước đây, cả ba trường hợp đều hiển thị dưới dạng mã 500, điều đó có nghĩa là logic retry của bạn không thể phân biệt giữa "hãy chờ và thử lại" với "hệ thống đã hỏng, hãy báo cáo lỗi". Giờ đây, nó đã có thể làm được.
Những thay đổi này có ý nghĩa gì đối với bạn
Nếu bạn đang chạy các scraper đối với các proxy xoay vòng, thay đổi thực tế là p95 và p99 của bạn đều giảm khoảng một nửa so với một tuần trước. Thời gian request trung bình giảm xuống. Các lượt retry do proxy chậm-nhưng-cuối-cùng-vẫn-hoạt-động giảm xuống. Tail latency, thứ khiến một công việc gồm 1.000 request mất một giờ thay vì 20 phút, cũng giảm theo.
Nếu bạn đang chạy Single, bạn sẽ thấy hiệu quả công việc của picker chủ yếu ở phần tail. p99 giảm xuống dưới 600 ms, điều đó có nghĩa là ngay cả 1% request kém may mắn của bạn giờ đây cũng phản hồi nhanh chóng. Single vốn đã nhanh. Giờ đây nó còn nhất quán.
Những hạn chế trung thực
Chúng tôi không khắc phục được mọi thứ. Một vài điểm cụ thể vẫn còn tồn tại:
Proxy Finder p99 vẫn ở mức khoảng 10 giây. Chúng tôi đã giảm một nửa, nhưng long tail là có thật. Một phần trong số đó là do chúng tôi (pool depth, picker noise trên các mục tiêu hiếm gặp). Phần lớn thì không phải: bản thân các trang web mục tiêu có thể tự chậm, có thể rate-limit các route cụ thể, có thể hiển thị các challenge page mất thời gian để kiểm tra, hoặc đơn giản là bị timeout. Hạ tầng của chúng tôi có thể chọn IP tốt nhất hiện có, nhưng nó không thể tăng tốc một máy chủ mục tiêu đang cân nhắc xem có nên phản hồi hay không. Nếu công việc của bạn phụ thuộc vào việc mọi request phải trả về dưới 5 giây, hãy thiết lập một khoảng timeout cho mỗi request phù hợp với mức độ chịu đựng của bạn và tin tưởng vào lớp retry.
Một số mục tiêu có tính thù địch, và điều đó hiển thị trong các con số của bạn. Như đã đề cập ở phần đầu, tỷ lệ thành công 99,91% không bao gồm một host đang tích cực challenge chúng tôi trong tuần này. Nếu tính cả host đó, tỷ lệ này sẽ giảm xuống còn khoảng 95%. Host đó không phải là duy nhất. Bất kỳ aggregator nào làm việc với dữ liệu web công cộng đều thấy điều này. Mục tiêu thay đổi theo từng tuần. Việc rebuild picker giúp hệ thống có cơ hội tốt hơn nhiều trong việc định tuyến xung quanh các mục tiêu thù địch, nhưng nó không thể vượt qua một trang web đã quyết định từ chối traffic hoàn toàn. Nhiệm vụ của chúng tôi là cung cấp cho bạn dữ liệu sạch nhất có thể trong các trường hợp hợp tác và fail fast trong các trường hợp thù địch.
So sánh trong cùng một ngày có thể có nhiễu. Khoảng thời gian 24 giờ mà chúng tôi hiển thị trong biểu đồ percentile là so sánh ngày hôm qua với ngày hôm trước. Các yếu tố ngày trong tuần, sự biến động của trang web mục tiêu và thành phần của pool đều thay đổi giữa hai khoảng thời gian bất kỳ. Chúng tôi tự tin vào xu hướng này (biểu đồ 7 ngày cho thấy một điểm uốn rõ ràng vào ngày 28 tháng 4), nhưng nếu bạn benchmark chúng tôi so với khối lượng công việc của riêng bạn, hãy thực hiện so sánh trong ít nhất một tuần.
Bước tiếp theo là gì
Việc viết lại picker là nền tảng. Một vài thứ chúng tôi đã xếp hàng đợi phía sau nó:
Một bản đồ quality score dùng chung trên các instance, để chúng học hỏi lẫn nhau thay vì xây dựng các bản đồ độc lập. Hiện tại, mỗi instance tự mang theo bức tranh riêng về việc proxy nào là tốt. Điều đó hoạt động được, nhưng gây lãng phí: mọi instance đều phải trả cùng một chi phí học hỏi song song.
Confidence-based picking, nơi chúng tôi ưu tiên các proxy thực sự đã được kiểm tra trong vài phút qua hơn là những proxy chúng tôi đang phỏng đoán. Điều này hữu ích cho những khách hàng có lưu lượng thấp, những người có traffic không tự duy trì trạng thái warm cho picker.
And longer-horizon: đưa nhiều quyết định hơn vào picker so với per-target quality score để nó trở thành một tín hiệu trong số nhiều tín hiệu khác (hồ sơ latency của mục tiêu, mô hình thời gian trong ngày, sức khỏe của phân đoạn pool). Hạ tầng hiện đã sẵn sàng để thực hiện việc này mà không làm chậm hot path.
Request rẻ nhất là request mà chúng tôi không phải retry. Việc rebuild picker là một canh bạc rằng dữ liệu tốt hơn tại thời điểm lựa chọn sẽ đánh bại nhiều nỗ lực thử lại sau đó. Bằng chứng trong 24 giờ đầu tiên cho thấy đó là một canh bạc đúng đắn.