4,2 millions de requêtes en 24 heures. Réponse moyenne : 774 ms. Taux de réussite : 99,91 %. La même charge de travail affichait une moyenne de 2,5 secondes durant les sept jours précédant notre refonte. Cela représente une baisse de 70 % du temps de réponse moyen, sur le même matériel, face aux mêmes sites cibles, avec le même pool de proxies. Nous avons refondu les parties du chemin de requête qui coûtaient discrètement leurs soirées à nos clients.
Voici un compte-rendu de ce qui a changé, de ce à quoi ressemblent réellement les chiffres, et des raisons pour lesquelles Single et Proxy Finder diffèrent.
Un mot sur les données d'abord. Les chiffres de cet article proviennent du trafic de production, à l'exclusion d'un hôte cible spécifique. Cet hôte a activement appliqué des rate limits et bloqué des requêtes toute la semaine, ce qui fausse toutes les métriques. Si on l'inclut, le taux de réussite chute à environ 95 %. Mais cet écart de 5 % n'est pas dû à une défaillance de notre infrastructure. C'est un site unique qui refuse les requêtes, quelle que soit la qualité de notre sélecteur. Nous l'avons retiré pour que vous puissiez voir ce que le système fait réellement sur des cibles coopératives.
Ce que montrent les données
Voici la moyenne quotidienne de notre trafic de production pour la semaine dernière :
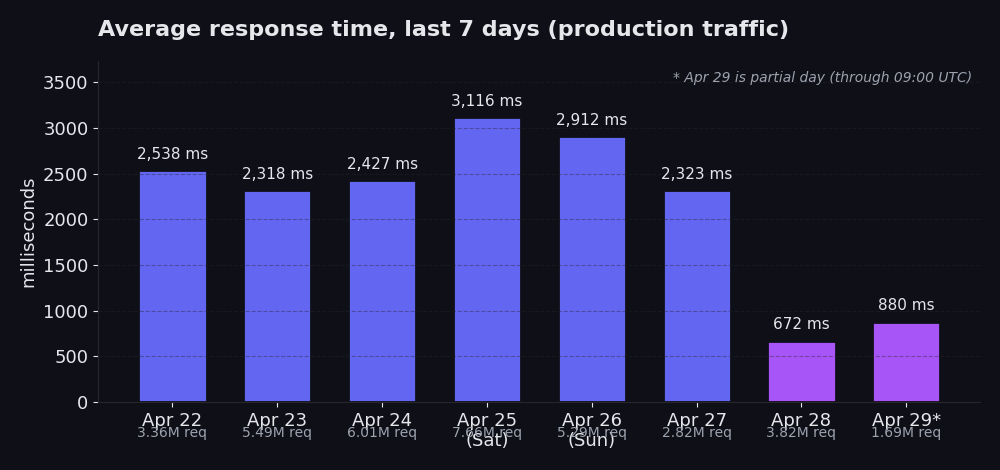
Du 22 au 27 avril : moyennes comprises entre 2 318 ms et 3 116 ms, trafic entre 2,8M et 7,7M de requêtes par jour. Le 25 avril se distingue avec 3 116 ms sur 7,7M de requêtes, ce qui correspond au pic du samedi (le volume du week-end est nettement plus élevé et fait grimper la moyenne). 28 avril : 672 ms sur 3,8M de requêtes. 29 avril (journée partielle, jusqu'à 09:00 UTC) : 880 ms sur 1,7M de requêtes jusqu'à présent.
Même architecture. Mêmes proxies. Mêmes sites cibles. Chemin de requête différent.
La répartition par percentile est plus nette que la moyenne. Les moyennes peuvent masquer les queues de distribution problématiques. Les percentiles ne le peuvent pas.
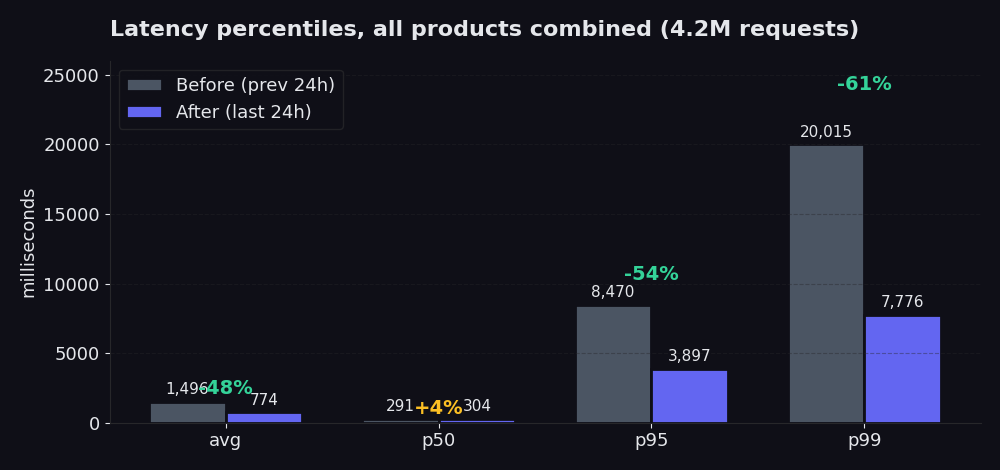
Le graphique compare les 24 heures suivant notre refonte aux 24 heures précédentes. Le p50 a à peine bougé (et a augmenté de 4 %, ce qui est une donnée honnête ; le chemin rapide fonctionnait déjà bien et le nouveau sélecteur consacre un peu plus d'efforts au départ pour économiser beaucoup sur la queue de distribution). La moyenne a chuté de 48 % sur cette période. Le p95 est passé de 8,5 secondes à 3,9 secondes, soit une réduction de 54 %. Le p99 est passé de 20 secondes à 7,8 secondes, soit une baisse de 61 %. C'est là que réside la vraie douleur, et c'est ce que vous ressentez réellement lorsque votre scraper attend le retour des 5 % de requêtes les plus lentes. Par rapport aux sept jours précédant la refonte (où la moyenne se maintenait autour de 2,5 secondes), la moyenne d'aujourd'hui de 774 ms représente une baisse de 70 %.
Le taux de réussite a également grimpé : de 98,85 % à 99,91 % sur la même période. Sur Proxy Finder spécifiquement, le taux a atteint 99,89 %. Sur Single, 99,96 %. C'est le chiffre dont nous sommes le plus fiers, car il indique à quelle fréquence nous renvoyons des données utiles dès la première tentative, sans avoir à réessayer.
Deux produits, deux profils de latence
Nous ne comparons pas Single et Proxy Finder l'un à l'autre. Ils résolvent des problèmes différents et ont des budgets de latence différents. Si vous utilisez l'un et regardez les chiffres de l'autre, vous ne regardez pas le bon tableau d'affichage.
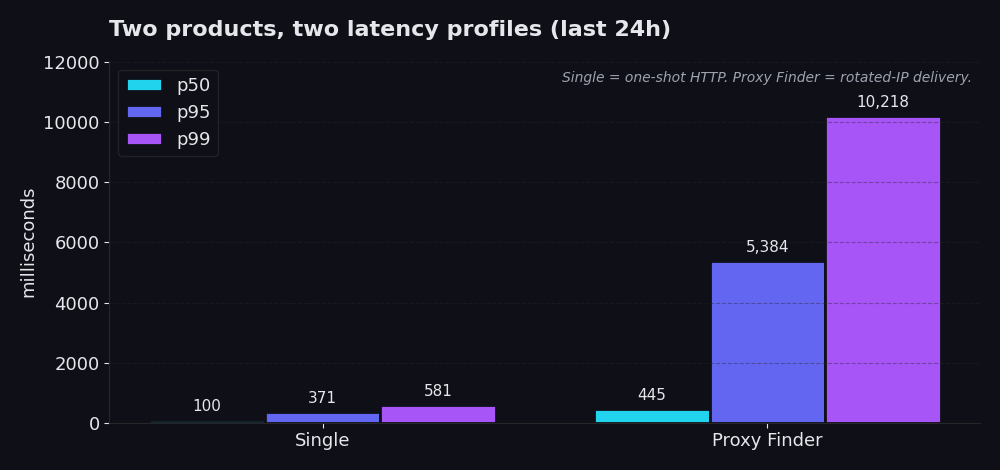
Single est une requête HTTP directe à travers notre infrastructure. Vous nous fournissez une URL et, dans environ 99 % des appels réels en production, un identifiant de proxy dont vous savez déjà qu'il fonctionne. Nous récupérons l'URL via ce proxy, vous obtenez la réponse. Pas de logique de rotation, pas de cascade de tentatives, pas de rotation incessante de proxies. Dernières 24 heures : p50 de 100 ms, p95 de 371 ms, p99 de 581 ms. La plupart des appels se terminent en moins d'un cinquième de seconde. Même le pire 1 % revient en moins de 600 ms.
Proxy Finder est la couche de découverte. Il fait tourner votre requête sur un pool de proxies publics, valide chaque candidat, réessaie en cas d'échec et renvoie la première réponse qui a réellement fonctionné, ainsi que l'identifiant du proxy qui l'a obtenue. p50 de 445 ms, p95 de 5,4 secondes, p99 de 10,2 secondes. Plus lent, car il doit l'être. Tout l'intérêt est que l'IP avec laquelle votre scraper interroge le site cible soit rotative, temporaire et jetable. Vous échangez quelques secondes de surcoût contre une résilience face aux listes de blocage et aux rate limits.
La raison pour laquelle Single est si rapide n'a rien de magique. C'est que Single fait confiance à ce que Proxy Finder a dû découvrir. Lorsque vous appelez Proxy Finder une fois et qu'il renvoie « ce proxy a fonctionné, voici son identifiant », les récupérations ultérieures vers la même cible via Single ignorent complètement l'étape de découverte. Vous allez directement vers le proxy qui a déjà passé la validation.
Comment les équipes les utilisent ensemble
La plupart des équipes qui ciblent fréquemment un site suivent un modèle en deux étapes. Le premier appel est exploratoire ; les suivants sont confirmés.
Le premier appel va vers Proxy Finder. Il effectue une rotation dans le pool, valide chaque candidat par rapport à vos règles d'acceptation et renvoie la réponse ainsi que l'identifiant du proxy qui a fonctionné. Cet identifiant est votre référence pour tout appel futur ciblant la même destination.
Chaque appel suivant passe par Single, avec l'identifiant du proxy associé. Pas de découverte, pas de validation, pas de cascade de tentatives. Nous acheminons votre requête via le proxy spécifié et vous renvoyons la réponse en streaming. C'est le chemin qui atteint 100 ms au p50.
Lorsque le proxy qui fonctionnait hier est bloqué aujourd'hui, vous basculez sur Proxy Finder pour un appel afin de redécouvrir un proxy fonctionnel, puis vous reprenez les requêtes Single avec le nouvel identifiant. Nous ne masquons pas l'obsolescence. Si un identifiant de proxy que vous nous avez fourni est hors service, nous vous le signalons rapidement afin que vous puissiez effectuer une rotation.
La répartition 99/1 (Single dominant en volume, Proxy Finder dominant pour la découverte) explique pourquoi nos chiffres pour Single se présentent ainsi. Ce n'est pas que Single soit intrinsèquement un produit plus rapide. C'est que Single représente le régime de croisière et Proxy Finder l'étape d'étalonnage. La plupart des charges de travail sont principalement en régime de croisière.
Si votre tâche consiste à « récupérer ce JSON à partir d'une API publique propre qui ne se soucie pas de l'identité de l'appelant », ignorez complètement le proxy et utilisez Single seul. Si votre tâche consiste à « interroger cette page protégée à partir d'un pool d'IP jetables sans vous faire repérer », combinez-les. Ce ne sont pas des alternatives. Ce sont des étapes d'un même workflow.
Ce que nous avons changé
L'essentiel du gain provient de la refonte de trois éléments dans le chemin de rotation des proxies. Aucune de ces idées n'était nouvelle. C'étaient simplement des tâches que nous avions repoussées.
Le pool a cessé de faire confiance aux données obsolètes. Avant la refonte, l'annuaire des proxies conservait les entrées plus longtemps qu'il ne l'aurait dû. Certaines de ces entrées n'étaient plus accessibles. En choisir une signifiait passer 15 à 30 secondes à le découvrir à vos dépens. Nous sommes passés à un modèle où le pool reflète ce qui est réellement actif en temps quasi réel, et le sélecteur privilégie les IP que nous avons récemment vues réussir.
Des scores de qualité par proxy, et plus seulement un état binaire actif/inactif. Auparavant, un proxy qui mettait 5 secondes à répondre était traité de la même manière qu'un proxy prenant 300 ms, tant que les deux finissaient par réussir. Désormais, le sélecteur suit également la latence. Les proxies lents mais fonctionnels sont repoussés en fin de file d'attente. Les plus rapides sont réutilisés tant qu'ils sont actifs. Cela a plus d'importance qu'il n'y paraît, car la longue traînée de la distribution de latence est principalement constituée de proxies lents mais fonctionnels que l'ancien sélecteur continuait de choisir.
Des scores de qualité par cible. Un proxy fiable sur un domaine peut être instable sur un autre. Les IP qui fonctionnent parfaitement sur un site peuvent être bloquées ou subir des rate limits sur un autre. Notre sélecteur suit désormais la réussite et la latence par hôte cible, et non plus seulement de manière globale. Lorsque vous demandez une récupération sur un domaine spécifique, nous choisissons parmi les proxies qui ont récemment obtenu de bons résultats sur ce domaine. Les proxies globalement performants restent en lice, mais un proxy ayant un excellent historique sur la cible exacte l'emporte sur un proxy performant de manière générale.
Une escalade des tentatives plus intelligente. Lorsqu'une requête échouait, nous lancions immédiatement des tentatives parallèles en rafale. C'était inefficace et, pire encore, un seul mauvais proxy pouvait déclencher une cascade de suivis qui échouaient tous à leur tour. Désormais, les tentatives s'enchaînent de manière séquentielle avec de courts délais d'attente (backoffs) entre chaque essai. Ainsi, un échec reste un échec et une tentative reste une tentative, sans effet multiplicateur.
Il existe une deuxième catégorie de changements qui mérite d'être mentionnée, même si elle est moins visible pour vous.
Résilience aux redémarrages. Auparavant, le redéploiement de notre infrastructure de requête entraînait une fenêtre de 5 à 15 minutes durant laquelle la carte des scores de qualité des proxies devait être entièrement reconstruite à partir de zéro. Pendant cette fenêtre, le sélecteur fonctionnait essentiellement à l'aveugle. Les clients constataient un pic de latence juste après chaque déploiement. Nous conservons désormais cette carte de qualité lors des redémarrages. Le système démarre à chaud. À compter d'aujourd'hui, nous pouvons déployer des modifications d'infrastructure en milieu de journée sans provoquer de pic de latence. Le test de redémarrage effectué ce matin a montré une micro-coupure de connexion de 15 secondes et aucun temps de récupération par la suite. C'est un changement discret mais significatif dans notre rythme de déploiement : nous n'avons plus besoin de planifier les redéploiements en fonction de votre trafic.
Des signaux d'erreur plus clairs. Lorsque quelque chose ne va pas au sein de notre infrastructure, votre logique de nouvelle tentative reçoit désormais le bon code d'état HTTP pour agir. Un backend temporairement indisponible renvoie un 503. Un backend ayant renvoyé un JSON malformé renvoie un 502. Une véritable erreur interne renvoie un 500. Auparavant, ces trois cas de figure apparaissaient comme des erreurs 500, ce qui signifiait que votre logique de nouvelle tentative ne pouvait pas distinguer « attendez et réessayez » de « le système est en panne, escaladez ». C'est désormais possible.
Ce que cela change pour vous
Si vous exécutez des scrapers avec des proxies rotatifs, le changement concret est que vos p95 et p99 sont chacun réduits de moitié environ par rapport à la semaine dernière. Le temps de requête moyen diminue. Les tentatives dues à des proxies lents mais qui finissent par fonctionner diminuent. La latence de queue, qui fait qu'une tâche de 1 000 requêtes prend une heure au lieu de 20 minutes, chute également.
Si vous utilisez Single, vous constaterez que le travail sur le sélecteur porte ses fruits principalement sur la queue de distribution. Le p99 est tombé sous la barre des 600 ms, ce qui signifie que même votre 1 % de requêtes malchanceuses revient désormais rapidement. Single était déjà rapide. Il est désormais constant.
Limites honnêtes
Nous n'avons pas tout résolu. Quelques points spécifiques s'appliquent toujours :
Le p99 de Proxy Finder reste d'environ 10 secondes. Nous l'avons réduit de moitié, mais la longue traînée est bien réelle. Une partie de cela nous incombe (profondeur du pool, bruit du sélecteur sur les cibles rares). Une grande partie n'est pas de notre ressort : les sites cibles peuvent être lents d'eux-mêmes, appliquer des rate limits sur des routes spécifiques, présenter des pages de défi (challenges) qui demandent du temps pour être inspectées, ou simplement expirer. Notre infrastructure peut choisir la meilleure IP disponible, mais elle ne peut pas accélérer un serveur cible qui tarde à répondre. Si votre tâche dépend du fait que chaque requête revienne en moins de 5 secondes, définissez un délai d'expiration (timeout) par requête adapté à votre tolérance et faites confiance à la couche de nouvelle tentative.
Certaines cibles sont hostiles, et cela se voit dans vos chiffres. Comme mentionné au début, le taux de réussite de 99,91 % exclut un hôte qui nous bloque activement cette semaine. Si on l'inclut, le taux chute à environ 95 %. Cet hôte n'est pas un cas unique. Tout agrégateur travaillant avec des données du web public y est confronté. La cible change d'une semaine à l'autre. La refonte du sélecteur donne au système de bien meilleures chances de contourner les cibles hostiles, mais elle ne peut pas contourner un site qui a décidé de refuser catégoriquement le trafic. Notre rôle est de vous fournir les données les plus propres possibles sur les cas coopératifs et d'échouer rapidement sur les cibles hostiles.
La comparaison d'un jour à l'autre comporte du bruit. La fenêtre de 24 heures présentée dans le graphique des percentiles compare hier à avant-hier. Les effets liés au jour de la semaine, les variations des sites cibles et la composition du pool changent d'une période à l'autre. Nous sommes confiants quant à la tendance (le graphique sur 7 jours montre un point d'inflexion net le 28 avril), mais si vous nous évaluez par rapport à votre propre charge de travail, effectuez la comparaison sur au moins une semaine.
Et ensuite ?
La réécriture du sélecteur est la fondation. Voici quelques éléments en attente juste après :
Une carte partagée des scores de qualité entre les instances, afin qu'elles apprennent les unes des autres au lieu de construire des cartes indépendantes. Actuellement, chaque instance possède sa propre vision des proxies performants. Cela fonctionne, mais c'est inefficace : chaque instance paie le même coût d'apprentissage en parallèle.
Une sélection basée sur la confiance, où nous privilégions les proxies que nous avons réellement testés au cours des dernières minutes par rapport à ceux sur lesquels nous faisons des suppositions. Utile pour les clients à faible volume dont le trafic ne suffit pas à maintenir le sélecteur chaud de lui-même.
Et à plus long terme : intégrer davantage de décisions au sein du sélecteur afin que le score de qualité par cible devienne un signal parmi d'autres (profil de latence de la cible, modèles temporels, santé des segments du pool). L'infrastructure existe désormais pour réaliser cela sans ralentir le chemin d'accès rapide.
La requête la moins coûteuse est celle que nous n'avons pas eu à réessayer. La refonte du sélecteur repose sur le pari que de meilleures données au moment du choix l'emportent sur la multiplication des tentatives après coup. Les premières 24 heures de preuves confirment que c'est le bon pari.